用图数据库解决关系型数据库存在的问题
用图数据库解决关系型数据库存在的问题
User-Order-Product
Rdbms
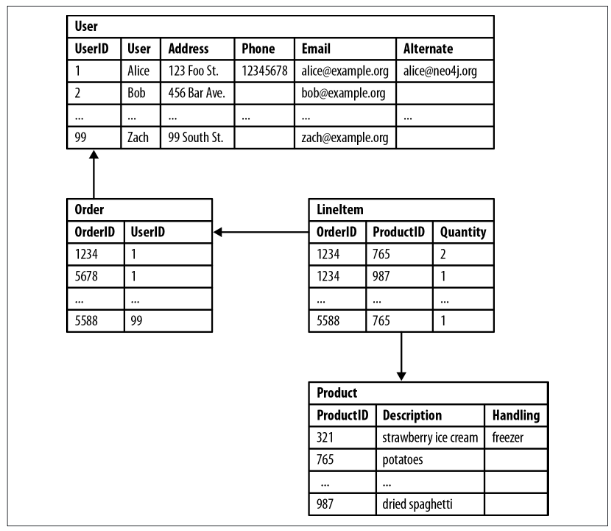
which customers buying this product also bought that product
Graph
(p2:Product)<-[*]-(u:User) -[*]->(p1:Product)
return u
Friend of friend
Rdbms
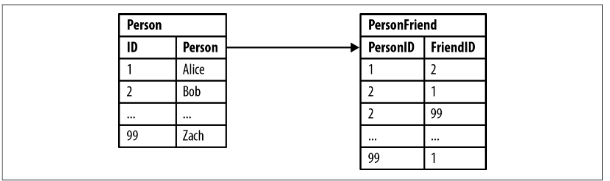
Alice’s friends-of-friends
SELECT p1.Person AS PERSON, p2.Person AS FRIEND_OF_FRIEND FROM PersonFriend pf1
JOIN Person p1 ON pf1.PersonID = p1.ID JOIN PersonFriend pf2 ON pf2.PersonID = pf1.FriendID
JOIN Person p2 ON pf2.FriendID = p2.ID
WHERE p1.Person = 'Alice' AND pf2.FriendID <> p1.ID
queries that extend to four, five, or six degrees of friendship deteriorate significantly due to the computational and space complexity of recursivelyjoining tables
Graph
(alice:Person)-[:Friend*2]->(p:Person)
return p
ACL
Rdbms
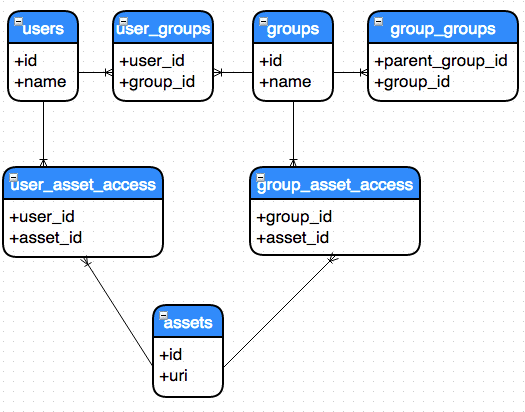
quick script to init schema and load data
CREATE TABLE USERS (id SERIAL, name varchar(50));
CREATE TABLE GROUPS (id SERIAL, name varchar(50));
CREATE TABLE USER_GROUPS (user_id integer, group_id integer);
CREATE TABLE GROUP_GROUPS (parent_group_id integer, group_id integer);
CREATE TABLE USER_ASSET_ACCESS(user_id integer, asset_id integer);
CREATE TABLE GROUP_ASSET_ACCESS(group_id integer, asset_id integer);
CREATE TABLE ASSETS (id SERIAL, uri varchar(1000));
INSERT INTO USERS (name) values('neo');
INSERT INTO USERS (name) values('morpheus');
INSERT INTO USERS (name) values('trinity');
INSERT INTO USERS (name) values('cypher');
INSERT INTO USERS (name) values('smith');
INSERT INTO GROUPS (name) values('agents');
INSERT INTO GROUPS (name) values('matrix');
INSERT INTO GROUPS (name) values('crew');
INSERT INTO GROUPS (name) values('the_one');
INSERT INTO USER_GROUPS values(1, 3);
INSERT INTO USER_GROUPS values(1, 4);
INSERT INTO USER_GROUPS values(2, 3);
INSERT INTO USER_GROUPS values(3, 3);
INSERT INTO USER_GROUPS values(4, 3);
INSERT INTO USER_GROUPS values(5, 1);
INSERT INTO GROUP_GROUPS values(2, 1);
INSERT INTO ASSETS (uri) values('/there/is/no/spoon');
INSERT INTO ASSETS (uri) values('/the/red/pill');
INSERT INTO ASSETS (uri) values('/mainframe');
INSERT INTO ASSETS (uri) values('/deja/vu');
INSERT INTO USER_ASSET_ACCESS values(1, 1);
INSERT INTO GROUP_ASSET_ACCESS values(2, 3);
INSERT INTO GROUP_ASSET_ACCESS values(3, 2);
INSERT INTO GROUP_ASSET_ACCESS values(4, 2); to create the schema in postgres, to follow along:
consider the queries we’ll need to run in order to decide whether a particular user has access to a particular asset. They might be directly connected via user_asset_access, or they might be in a group that has access via group_asset_access. Or they may even be in a group that’s part of a larger group that has access via group_asset_access, and so on…
So you end up writing long queries in order to determine whether someone has access to a particular asset. Here, if any counts returned are >0, they have access:
SELECT count(1)
FROM users u, user_asset_access uaa, assets a
WHERE u.id = uaa.user_id
AND uaa.asset_id = a.id
AND a.uri = '/mainframe'
AND u.name = 'smith'
UNION ALL
SELECT count(1)
FROM users u, user_groups ug, groups g, group_asset_access gaa, assets a
WHERE u.id = ug.user_id
AND g.id = ug.group_id
AND gaa.asset_id = a.id
AND gaa.group_id = g.id
AND a.uri = '/mainframe'
AND u.name = 'smith'
UNION ALL
SELECT count(1)
FROM users u, user_groups ug, groups g, groups pg, group_groups gg, group_asset_access gaa, assets a
WHERE u.id = ug.user_id
AND g.id = ug.group_id
AND gg.parent_group_id = pg.id
AND gg.group_id = g.id
AND gaa.asset_id = a.id
AND gaa.group_id = pg.id
AND a.uri = '/mainframe'
AND u.name = 'smith'
Graph
Migrating data to Neo4j
let’s construct our export and import queries to load our data from a SQL database to Neo4j. In postgres, there is a convenient CSV export function called COPY
wfreeman=# COPY users TO '/tmp/users.csv' WITH CSV;
COPY 5
wfreeman=# COPY assets TO '/tmp/assets.csv' WITH CSV;
COPY 4
wfreeman=# COPY groups TO '/tmp/groups.csv' WITH CSV;
COPY 4
wfreeman=# COPY user_groups TO '/tmp/user_groups.csv' WITH CSV;
COPY 6
wfreeman=# COPY group_groups TO '/tmp/group_groups.csv' WITH CSV;
COPY 1
wfreeman=# COPY group_asset_access TO '/tmp/group_asset_access.csv' WITH CSV;
COPY 3
wfreeman=# COPY user_asset_access TO '/tmp/user_asset_access.csv' WITH CSV;
COPY 1
First we’ll make some unique constraints (which come with indexes), as well as some indexes for our non-unique data:
CREATE CONSTRAINT ON (u:User) ASSERT u.id IS UNIQUE;
CREATE CONSTRAINT ON (g:Group) ASSERT g.id IS UNIQUE;
CREATE CONSTRAINT ON (a:Asset) ASSERT a.id IS UNIQUE;
CREATE INDEX ON :User(name);
CREATE INDEX ON :Group(name);
CREATE INDEX ON :Asset(uri);
We’ll need to use LOAD CSV along with the MERGE clause to bring the data in.
LOAD CSV FROM 'file:///tmp/users.csv' as line
MERGE (:User {id:toInt(line[0]), name:line[1]});
LOAD CSV FROM 'file:///tmp/groups.csv' as line
MERGE (:Group {id:toInt(line[0]), name:line[1]});
LOAD CSV FROM 'file:///tmp/assets.csv' as line
MERGE (:Asset {id:toInt(line[0]), uri:line[1]});
LOAD CSV FROM 'file:///tmp/user_asset_access.csv' as line
MATCH (u:User {id:toInt(line[0])}), (a:Asset {id:toInt(line[1])})
MERGE (u)-[:HAS_ACCESS]->(a);
LOAD CSV FROM 'file:///tmp/group_asset_access.csv' as line
MATCH (g:Group {id:toInt(line[0])}), (a:Asset {id:toInt(line[1])})
MERGE (g)-[:HAS_ACCESS]->(a);
LOAD CSV FROM 'file:///tmp/user_groups.csv' as line
MATCH (u:User {id:toInt(line[0])}), (g:Group {id:toInt(line[1])})
MERGE (u)-[:IS_MEMBER]->(g);
LOAD CSV FROM 'file:///tmp/group_groups.csv' as line
MATCH (p:Group {id:toInt(line[0])}), (g:Group {id:toInt(line[1])})
MERGE (g)-[:IS_MEMBER]->(p);
Running Cypher
Once all of the data is imported, we can run some queries in the browser.Let’s see whether Neo has access to /the/red/pill, using the shortestPath function to optimize the search (note the difference in complexity between this query and the SQL that accomplished a similar result):
MATCH shortestPath((neo:User {name:'neo'})-[:HAS_ACCESS|IS_MEMBER*]->(a:Asset {uri:'/the/red/pill'}))
RETURN count(*) > 0 as hasAccess
We have :User(name) and :Asset(uri) indexes, so Cypher can look those up quickly via their respective indexes. Once it has those starting points, it will use the shortestPath() matcher to find a single path that matches, following relationships of either:HAS_ACCESS or :IS_MEMBER (which is enough to determine whether Neo has access to /the/red/pill).
Who has access to /the/red/pill?
MATCH shortestPath((u:User)-[:HAS_ACCESS|IS_MEMBER*]->(a:Asset {uri:'/the/red/pill'}))
RETURN u.name
Recommendation
The Model
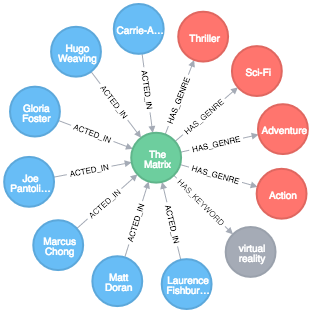
Nodes
MoviePersonGenreKeyword
Relationships
(:Person)-[:ACTED_IN {role:"some role"}]->(:Movie)(:Person)-[:DIRECTED]->(:Movie)(:Person)-[:WRITER_OF]->(:Movie)(:Person)-[:PRODUCED]->(:Movie)(:MOVIE)-[:HAS_GENRE]->(:Genre)
Recommendation Cypher
User-Centric, User-Based Recommendations
Based on my similarity to other users, user Sherman might be interested in movies rated highly by users with similar ratings as himself.
MATCH (me:User {username:'Sherman'})-[my:RATED]->(m:Movie)
MATCH (other:User)-[their:RATED]->(m)
WHERE me <> other
AND abs(my.rating - their.rating) < 2
WITH other,m
MATCH (other)-[otherRating:RATED]->(movie:Movie)
WHERE movie <> m
WITH avg(otherRating.rating) AS avgRating, movie
RETURN movie
ORDER BY avgRating desc
LIMIT 25
Movie-Centric, Keyword-Based Recommendations
Site visitors interested in movies like Elysium will likely be interested in movies with similar keywords.
MATCH (m:Movie {title:'Elysium'})
MATCH (m)-[:HAS_KEYWORD]->(k:Keyword)
MATCH (movie:Movie)-[r:HAS_KEYWORD]->(k)
WHERE m <> movie
WITH movie, count(DISTINCT r) AS commonKeywords
RETURN movie
ORDER BY commonKeywords DESC
LIMIT 25
User-Centric, Keyword-Based Recommendations
Sherman has seen many movies, and is looking for movies similar to the ones he has already watched.
MATCH (u:User {username:'Sherman'})-[:RATED]->(m:Movie)
MATCH (m)-[:HAS_KEYWORD]->(k:Keyword)
MATCH (movie:Movie)-[r:HAS_KEYWORD]->(k)
WHERE m <> movie
WITH movie, count(DISTINCT r) AS commonKeywords
RETURN movie
ORDER BY commonKeywords DESC
LIMIT 25