Scrapy In-depth Analysis
Scrapy In-depth Analysis
spider examples and patterns
import scrapy
class AuthorSpider(scrapy.Spider):
name = 'author'
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
# follow links to author pages
for href in response.css('.author+a::attr(href)').extract():
yield scrapy.Request(response.urljoin(href),
callback=self.parse_author)
# follow pagination links
next_page = response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
def parse_author(self, response):
def extract_with_css(query):
return response.css(query).extract_first().strip()
yield {
'name': extract_with_css('h3.author-title::text'),
'birthdate': extract_with_css('.author-born-date::text'),
'bio': extract_with_css('.author-description::text'),
}
For spiders, the scraping cycle goes through something like this:
- You start by generating the initial Requests to crawl the first URLs, and specify a callback function to be called with the response downloaded from those requests. The first requests to perform are obtained by calling the start_requests() method which (by default) generates Request for the URLs specified in the start_urls and the parse method as callback function for the Requests.
- In the callback function, you parse the response (web page) and return either dicts with extracted data, Item objects, Request objects, or an iterable of these objects. Those Requests will also contain a callback (maybe the same) and will then be downloaded by Scrapy and then their response handled by the specified callback.
- In callback functions, you parse the page contents, typically using Selectors (but you can also use BeautifulSoup, lxml or whatever mechanism you prefer) and generate items with the parsed data.
- Finally, the items returned from the spider will be typically persisted to a database (in some Item Pipeline) or written to a file using Feed exports.
architecture
来看一看Scrapy的架构图:
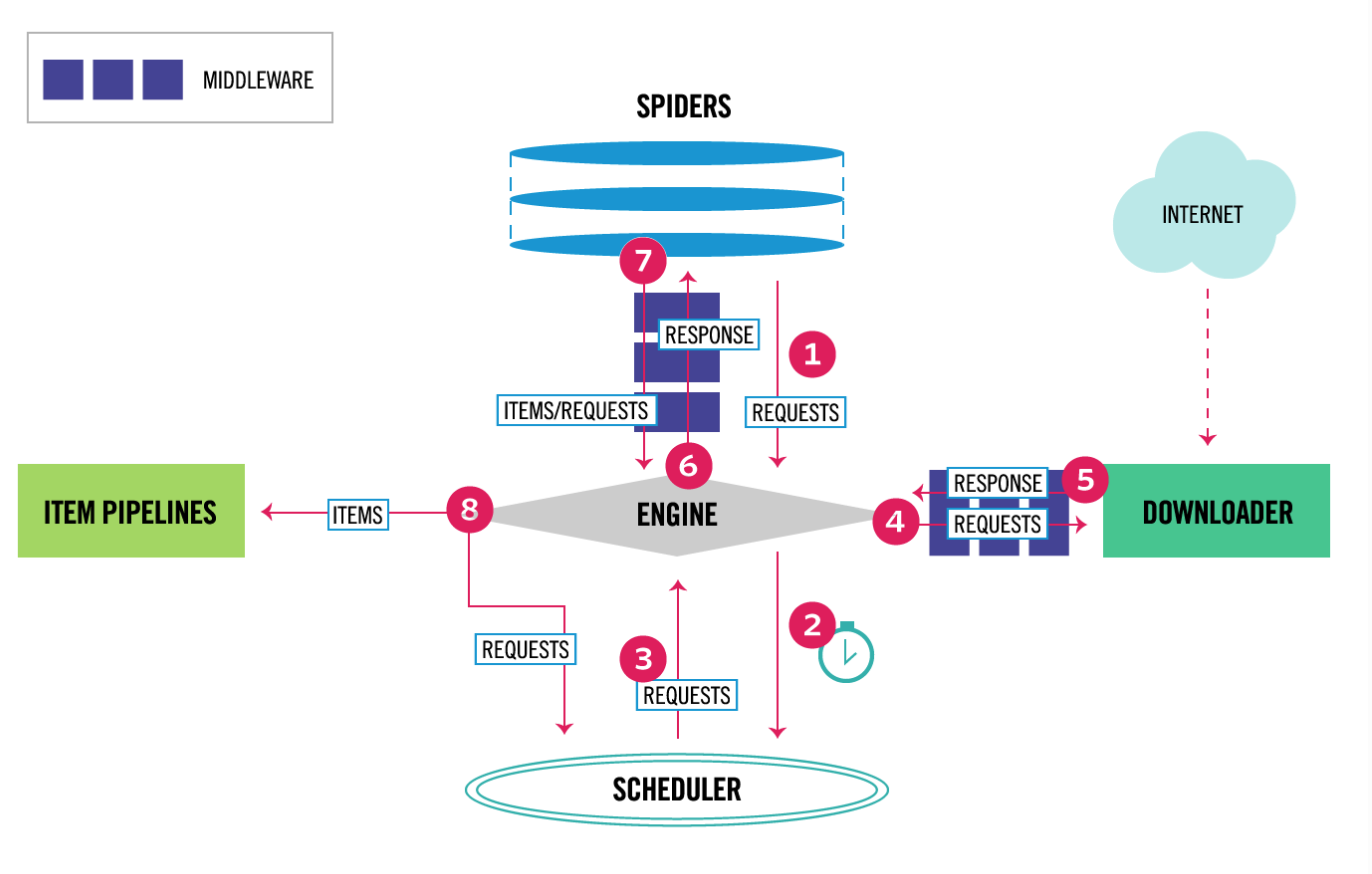
核心组件 Scrapy有以下几大组件:
- Engine:核心引擎,负责控制和调度各个组件,保证数据流转;
- Scheduler:负责管理任务、过滤任务、输出任务的调度器,存储、去重任务都在此控制;
- Downloader:下载器,负责在网络上下载网页数据,输入待下载URL,输出下载结果;
- Spiders:用户自己编写的爬虫脚本,可自定义抓取意图;
- Item Pipeline:负责输出结构化数据,可自定义输出位置;
除此之外,还有两大中间件组件:
- DownloaderMiddlewares:介于引擎和下载器之间,可以在网页在下载前、后进行逻辑处理;
- SpiderMiddlewares:介于引擎和爬虫之间,可以在调用爬虫输入下载结果和输出请求/数据时进行逻辑处理;
数据流转 按照架构图的序号,数据流转大概是这样的:
- 引擎从自定义爬虫中获取初始化请求(也叫种子URL);
- 引擎把该请求放入调度器中,同时引擎向调度器获取一个待下载的请求(这两部是异步执行的);
- 调度器返回给引擎一个待下载的请求;
- 引擎发送请求给下载器,中间会经过一系列下载器中间件;
- 这个请求通过下载器下载完成后,生成一个响应对象,返回给引擎,这中间会再次经过一系列下载器中间件;
- 引擎接收到下载返回的响应对象后,然后发送给爬虫,执行自定义爬虫逻辑,中间会经过一系列爬虫中间件;
- 爬虫执行对应的回调方法,处理这个响应,完成用户逻辑后,会生成结果对象或新的请求对象给引擎,再次经过一系列爬虫中间件;
- 引擎把爬虫返回的结果对象交由结果处理器处理,把新的请求对象通过引擎再交给调度器;
- 从1开始重复执行,直到调度器中没有新的请求处理;
核心组件交互图
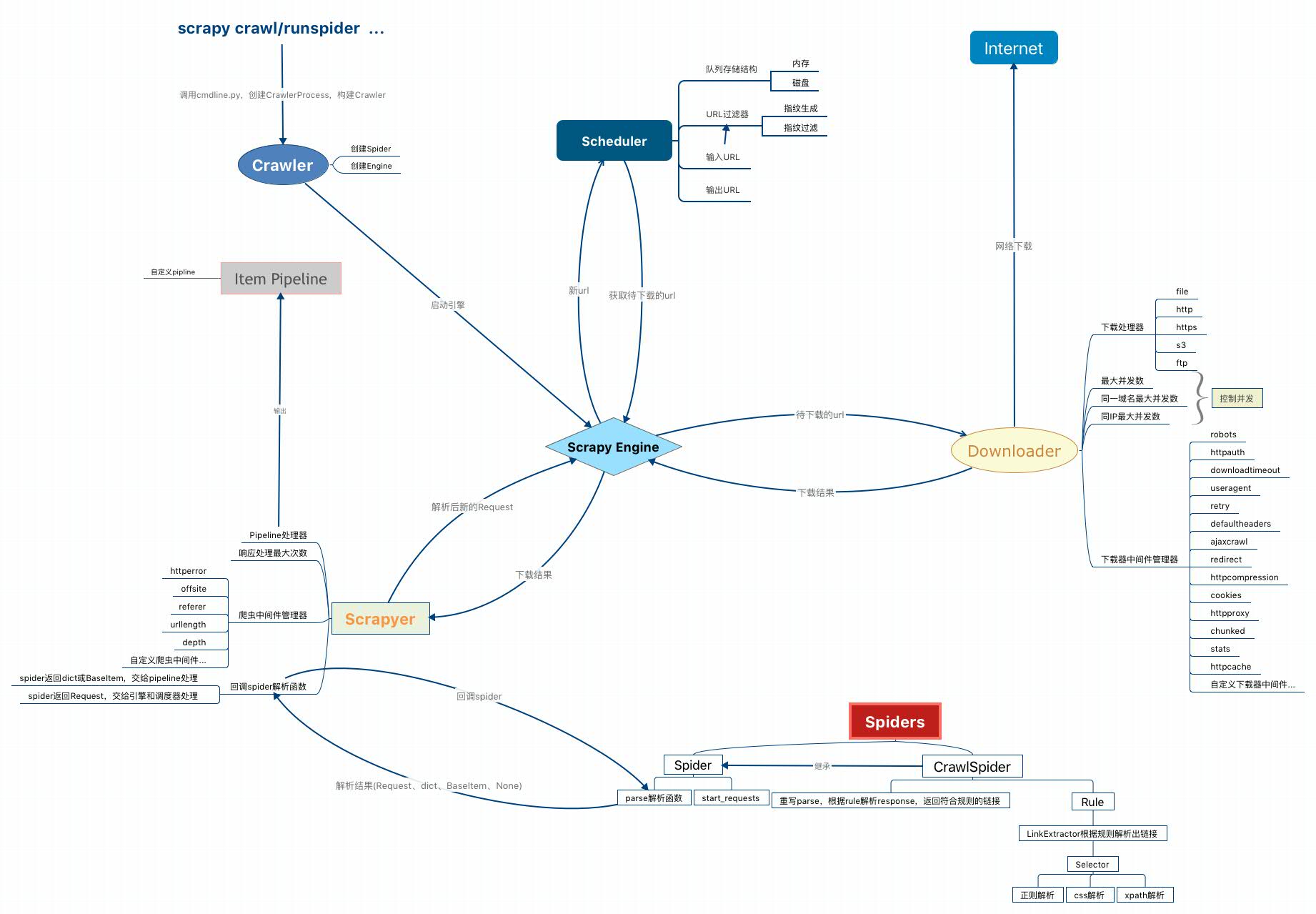
核心类图
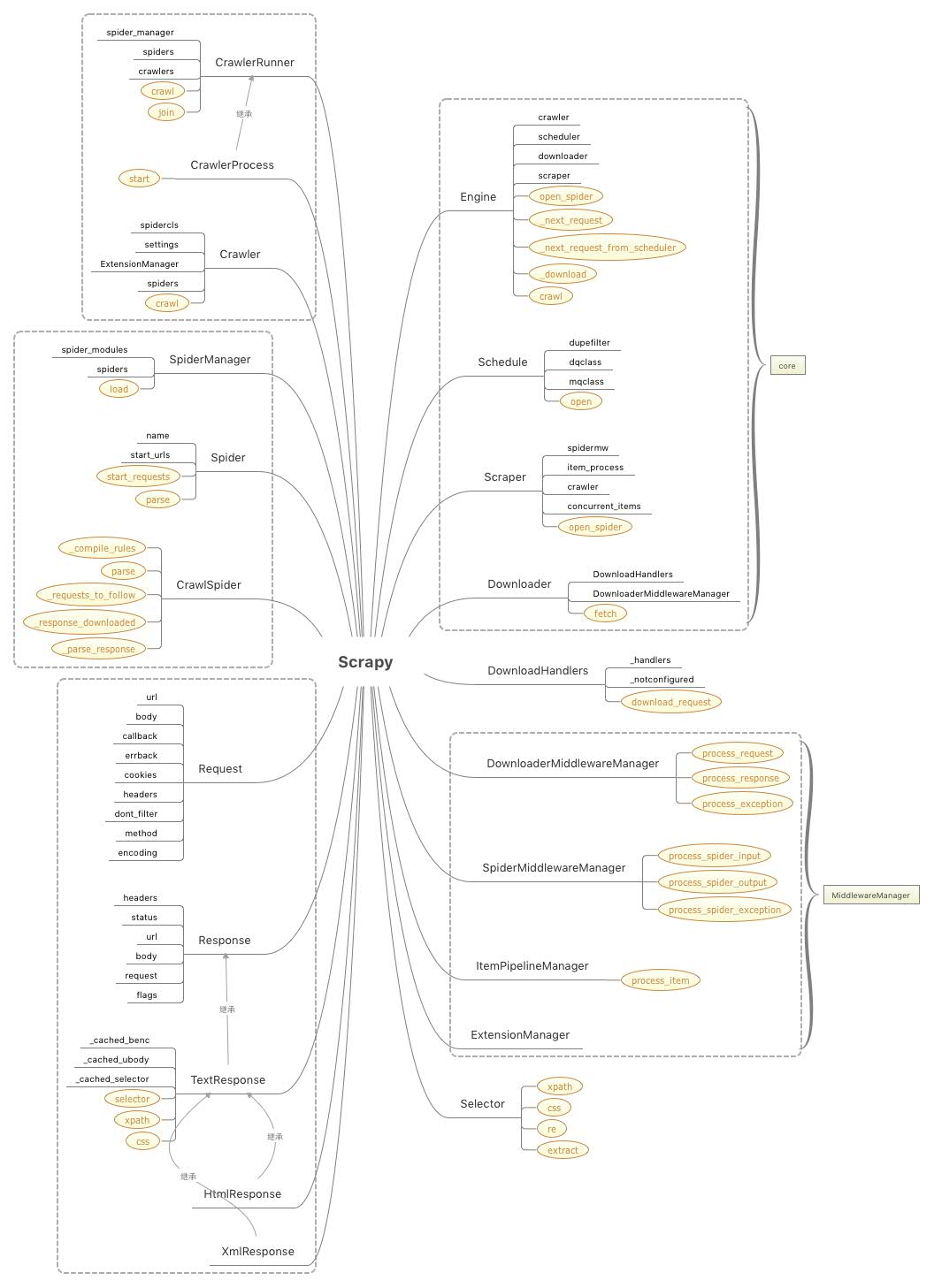
source code analysis
entrance
在执行scrapy命令时,调用流程如下:
- 调用cmdline.py的execute方法
- 调用命令实例解析命令行
- 构建CrawlerProcess实例,调用crawl和start方法
而crawl方法最终是调用了Cralwer实例的crawl,这个方法最终把控制权交由Engine,而start方法注册好协程池,开始异步调度。
我们来看Cralwer的crawl方法:
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
# 创建爬虫实例
self.spider = self._create_spider(*args, **kwargs)
# 创建引擎
self.engine = self._create_engine()
# 调用spider的start_requests,获取种子URL
start_requests = iter(self.spider.start_requests())
# 调用engine的open_spider,交由引擎调度
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
if six.PY2:
exc_info = sys.exc_info()
self.crawling = False
if self.engine is not None:
yield self.engine.close()
if six.PY2:
six.reraise(*exc_info)
raise
在把控制权交给引擎调度之前,先创建出爬虫实例,然后创建引擎实例,然后调用了spider的start_requests方法,这个方法就是我们平时写的最多爬虫类的父类,它在spiders/init.py中:
def start_requests(self):
# 根据定义好的start_urls属性,生成种子URL对象
for url in self.start_urls:
yield self.make_requests_from_url(url)
def make_requests_from_url(self, url):
# 构建Request对象
return Request(url, dont_filter=True)
在这里我们能看到,平时我们必须要定义的start_urls,原来是在这里拿来构建Request的.当然,你也可以在子类重写start_requests以及make_requests_from_url这2个方法,来构建种子请求。
engine
回到crawl方法,构建好种子请求对象后,调用了engine的open_spider方法:
@defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
assert self.has_capacity(), "No free spider slot when opening %r" % \
spider.name
logger.info("Spider opened", extra={'spider': spider})
# 注册_next_request调度方法,循环调度
nextcall = CallLaterOnce(self._next_request, spider)
# 初始化scheduler
scheduler = self.scheduler_cls.from_crawler(self.crawler)
# 调用爬虫中间件,处理种子请求
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
# 封装Slot对象
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
# 调用scheduler的open
yield scheduler.open(spider)
# 调用scrapyer的open
yield self.scraper.open_spider(spider)
# 调用stats的open
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
# 发起调度
slot.nextcall.schedule()
slot.heartbeat.start(5)
这里第一步是构建了CallLaterOnce,把_next_request注册进去,看此类的实现:
class CallLaterOnce(object):
# 在twisted的reactor中循环调度一个方法
def __init__(self, func, *a, **kw):
self._func = func
self._a = a
self._kw = kw
self._call = None
def schedule(self, delay=0):
# 上次发起调度,才可再次继续调度
if self._call is None:
# 注册self到callLater中
self._call = reactor.callLater(delay, self)
def cancel(self):
if self._call:
self._call.cancel()
def __call__(self):
# 上面注册的是self,所以会执行__call__
self._call = None
return self._func(*self._a, **self._kw)
封装了循环执行的方法类,并且注册的方法会在twisted的reactor中异步执行,以后执行只需调用schedule方法,就会注册self到reactor的callLater中,然后它会执行__call__方法,进而执行我们注册的方法。而这里我们注册的方法是引擎的_next_request,也就是说,此方法会循环调度,直到所有请求处理完成程序退出。
scheduler
接着调用了Scheduler的open:
def open(self, spider):
self.spider = spider
# 实例化优先级队列
self.mqs = self.pqclass(self._newmq)
# 如果定义了dqdir则实例化基于磁盘的队列
self.dqs = self._dq() if self.dqdir else None
# 调用请求指纹过滤器的open方法
return self.df.open()
def _dq(self):
# 实例化磁盘队列
activef = join(self.dqdir, 'active.json')
if exists(activef):
with open(activef) as f:
prios = json.load(f)
else:
prios = ()
q = self.pqclass(self._newdq, startprios=prios)
if q:
logger.info("Resuming crawl (%(queuesize)d requests scheduled)",
{'queuesize': len(q)}, extra={'spider': self.spider})
return q
在open方法中,实例化出优先级队列以及根据dqdir决定是否使用磁盘队列,然后调用了请求指纹过滤器的open,请求过滤器提供了请求过滤的具体实现方式,Scrapy默认提供了RFPDupeFilter过滤器实现过滤重复请求的逻辑
Scraper
再来看Scraper的open_spider:
@defer.inlineCallbacks
def open_spider(self, spider):
self.slot = Slot()
# 调用所有pipeline的open_spider
yield self.itemproc.open_spider(spider)
这里的工作主要是Scraper调用所有Pipeline的open_spider方法,也就是说,如果我们定义了多个Pipeline输出类,可重写open_spider完成每个Pipeline处理输出开始的初始化工作。
main loop
完成调用一系列组件的open方法后,最后调用了nextcall.schedule()开始调度,也就是循环执行在引擎上注册的_next_request方法:
def _next_request(self, spider):
# 此方法会循环调度
slot = self.slot
if not slot:
return
# 暂停
if self.paused:
return
# 是否等待
while not self._needs_backout(spider):
# 从scheduler中获取request
# 注意:第一次获取时,是没有的,也就是会break出来
# 从而执行下面的逻辑
if not self._next_request_from_scheduler(spider):
break
# 如果start_requests有数据且不需要等待
if slot.start_requests and not self._needs_backout(spider):
try:
# 获取下一个种子请求
request = next(slot.start_requests)
except StopIteration:
slot.start_requests = None
except Exception:
slot.start_requests = None
logger.error('Error while obtaining start requests',
exc_info=True, extra={'spider': spider})
else:
# 调用crawl,实际是把request放入scheduler的队列中
self.crawl(request, spider)
# 空闲则关闭spider
if self.spider_is_idle(spider) and slot.close_if_idle:
self._spider_idle(spider)
def _needs_backout(self, spider):
# 是否需要等待,取决4个条件
# 1. Engine是否stop
# 2. slot是否close
# 3. downloader下载超过预设
# 4. scraper处理response超过预设
slot = self.slot
return not self.running \
or slot.closing \
or self.downloader.needs_backout() \
or self.scraper.slot.needs_backout()
def _next_request_from_scheduler(self, spider):
slot = self.slot
# 从scheduler拿出下个request
request = slot.scheduler.next_request()
if not request:
return
# 下载
d = self._download(request, spider)
# 注册成功、失败、出口回调方法
d.addBoth(self._handle_downloader_output, request, spider)
d.addErrback(lambda f: logger.info('Error while handling downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.remove_request(request))
d.addErrback(lambda f: logger.info('Error while removing request from slot',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.nextcall.schedule())
d.addErrback(lambda f: logger.info('Error while scheduling new request',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
return d
def crawl(self, request, spider):
assert spider in self.open_spiders, \
"Spider %r not opened when crawling: %s" % (spider.name, request)
# request放入scheduler队列,调用nextcall的schedule
self.schedule(request, spider)
self.slot.nextcall.schedule()
def schedule(self, request, spider):
self.signals.send_catch_log(signal=signals.request_scheduled,
request=request, spider=spider)
# 调用scheduler的enqueue_request,把request放入scheduler队列
if not self.slot.scheduler.enqueue_request(request):
self.signals.send_catch_log(signal=signals.request_dropped,
request=request, spider=spider)
_next_request方法首先调用_needs_backout方法检查是否需要等待,等待的条件有:
- 引擎是否主动关闭
- Slot是否关闭
- 下载器网络下载超过预设参数
- Scraper处理输出超过预设参数
如果不需要等待,则调用_next_request_from_scheduler,此方法从名字上就能看出,主要是从Schduler中获取Request。
这里要注意,在第一次调用此方法时,Scheduler中是没有放入任何Request的,这里会直接break出来,执行下面的逻辑,而下面就会调用crawl方法,实际是把请求放到Scheduler的请求队列,放入队列的过程会经过请求过滤器校验是否重复。
下次再调用_next_request_from_scheduler时,就能从Scheduler中获取到下载请求,然后执行下载动作。
先来看第一次调度,执行crawl:
def crawl(self, request, spider):
assert spider in self.open_spiders, \
"Spider %r not opened when crawling: %s" % (spider.name, request)
# 放入Scheduler队列
self.schedule(request, spider)
# 进行下一次调度
self.slot.nextcall.schedule()
def schedule(self, request, spider):
self.signals.send_catch_log(signal=signals.request_scheduled,
request=request, spider=spider)
# 放入Scheduler队列
if not self.slot.scheduler.enqueue_request(request):
self.signals.send_catch_log(signal=signals.request_dropped,
request=request, spider=spider)
request queue
调用引擎的crawl实际就是把请求放入Scheduler的队列中
def enqueue_request(self, request):
# 请求入队,若请求过滤器验证重复,返回False
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
# 磁盘队列是否入队成功
dqok = self._dqpush(request)
if dqok:
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
# 没有定义磁盘队列,则使用内存队列
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
def _dqpush(self, request):
# 是否定义磁盘队列
if self.dqs is None:
return
try:
# Request对象转dict
reqd = request_to_dict(request, self.spider)
# 放入磁盘队列
self.dqs.push(reqd, -request.priority)
except ValueError as e: # non serializable request
if self.logunser:
msg = ("Unable to serialize request: %(request)s - reason:"
" %(reason)s - no more unserializable requests will be"
" logged (stats being collected)")
logger.warning(msg, {'request': request, 'reason': e},
exc_info=True, extra={'spider': self.spider})
self.logunser = False
self.stats.inc_value('scheduler/unserializable',
spider=self.spider)
return
else:
return True
def _mqpush(self, request):
# 入内存队列
self.mqs.push(request, -request.priority)
在之前将核心组件实例化时有说到,调度器主要定义了2种队列:基于磁盘队列、基于内存队列。如果在实例化Scheduler时候传入jobdir,则使用磁盘队列,否则使用内存队列,默认使用内存队列。
url dedup
在入队之前,首先通过请求指纹过滤器检查请求是否重复,也就是调用了过滤器的request_seen:
def request_seen(self, request):
# 生成请求指纹
fp = self.request_fingerprint(request)
# 请求指纹如果在指纹集合中,则认为重复
if fp in self.fingerprints:
return True
# 不重复则记录此指纹
self.fingerprints.add(fp)
# 实例化如果有path则把指纹写入文件
if self.file:
self.file.write(fp + os.linesep)
def request_fingerprint(self, request):
# 调用utils.request的request_fingerprint
return request_fingerprint(request)
def request_fingerprint(request, include_headers=None):
"""生成请求指纹"""
# 指纹生成是否包含headers
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
# 使用sha1算法生成指纹
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
这个过滤器先是通过Request对象生成一个请求指纹,在这里使用sha1算法,并记录到指纹集合,每次请求入队前先到这里验证一下指纹集合,如果已存在,则认为请求重复,则不会重复入队列。
download request
第一次请求进来后,肯定是不重复的,那么则会正常进入调度器队列。然后再进行下一次调度,再次调用_next_request_from_scheduler方法,此时调用调度器的next_request方法,就是从调度器队列中取出一个请求,这次就要开始进行网络下载了,也就是调用_download:
def _download(self, request, spider):
# 下载请求
slot = self.slot
slot.add_request(request)
def _on_success(response):
# 成功回调,结果必须是Request或Response
assert isinstance(response, (Response, Request))
if isinstance(response, Response):
# 如果下载后结果为Response,返回Response
response.request = request
logkws = self.logformatter.crawled(request, response, spider)
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
self.signals.send_catch_log(signal=signals.response_received, \
response=response, request=request, spider=spider)
return response
def _on_complete(_):
# 此次下载完成后,继续进行下一次调度
slot.nextcall.schedule()
return _
# 调用Downloader进行下载
dwld = self.downloader.fetch(request, spider)
# 注册成功回调
dwld.addCallbacks(_on_success)
# 结束回调
dwld.addBoth(_on_complete)
return dwld
在进行网络下载时,调用了Downloader的fetch:
def fetch(self, request, spider):
def _deactivate(response):
# 下载结束后删除此记录
self.active.remove(request)
return response
# 下载前记录处理中的请求
self.active.add(request)
# 调用下载器中间件download,并注册下载成功的回调方法是self._enqueue_request
dfd = self.middleware.download(self._enqueue_request, request, spider)
# 注册结束回调
return dfd.addBoth(_deactivate)
下载过程中,首先先找到所有定义好的下载器中间件,包括内置定义好的,也可以自己扩展下载器中间件,下载前先依次执行process_request方法,可对request进行加工、处理、校验等操作:
def download(self, download_func, request, spider):
@defer.inlineCallbacks
def process_request(request):
# 如果下载器中间件有定义process_request,则依次执行
for method in self.methods['process_request']:
response = yield method(request=request, spider=spider)
assert response is None or isinstance(response, (Response, Request)), \
'Middleware %s.process_request must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, response.__class__.__name__)
# 如果下载器中间件有返回值,直接返回此结果
if response:
defer.returnValue(response)
# 如果下载器中间件没有返回值,则执行注册进来的方法,也就是Downloader的_enqueue_request
defer.returnValue((yield download_func(request=request,spider=spider)))
@defer.inlineCallbacks
def process_response(response):
assert response is not None, 'Received None in process_response'
if isinstance(response, Request):
defer.returnValue(response)
# 如果下载器中间件有定义process_response,则依次执行
for method in self.methods['process_response']:
response = yield method(request=request, response=response,
spider=spider)
assert isinstance(response, (Response, Request)), \
'Middleware %s.process_response must return Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, type(response))
if isinstance(response, Request):
defer.returnValue(response)
defer.returnValue(response)
@defer.inlineCallbacks
def process_exception(_failure):
exception = _failure.value
# 如果下载器中间件有定义process_exception,则依次执行
for method in self.methods['process_exception']:
response = yield method(request=request, exception=exception,
spider=spider)
assert response is None or isinstance(response, (Response, Request)), \
'Middleware %s.process_exception must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, type(response))
if response:
defer.returnValue(response)
defer.returnValue(_failure)
# 注册执行、错误、回调方法
deferred = mustbe_deferred(process_request, request)
deferred.addErrback(process_exception)
deferred.addCallback(process_response)
return deferred
然后发起真正的网络下载,也就是第一个参数download_func,在这里是Downloader的_enqueue_request方法:
def _enqueue_request(self, request, spider):
# 加入下载请求队列
key, slot = self._get_slot(request, spider)
request.meta['download_slot'] = key
def _deactivate(response):
slot.active.remove(request)
return response
slot.active.add(request)
deferred = defer.Deferred().addBoth(_deactivate)
# 下载队列
slot.queue.append((request, deferred))
# 处理下载队列
self._process_queue(spider, slot)
return deferred
def _process_queue(self, spider, slot):
if slot.latercall and slot.latercall.active():
return
# 如果延迟下载参数有配置,则延迟处理队列
now = time()
delay = slot.download_delay()
if delay:
penalty = delay - now + slot.lastseen
if penalty > 0:
slot.latercall = reactor.callLater(penalty, self._process_queue, spider, slot)
return
# 处理下载队列
while slot.queue and slot.free_transfer_slots() > 0:
slot.lastseen = now
# 从下载队列中取出下载请求
request, deferred = slot.queue.popleft()
# 开始下载
dfd = self._download(slot, request, spider)
dfd.chainDeferred(deferred)
# 延迟
if delay:
self._process_queue(spider, slot)
break
def _download(self, slot, request, spider):
# 注册方法,调用handlers的download_request
dfd = mustbe_deferred(self.handlers.download_request, request, spider)
# 注册下载完成回调方法
def _downloaded(response):
self.signals.send_catch_log(signal=signals.response_downloaded,
response=response,
request=request,
spider=spider)
return response
dfd.addCallback(_downloaded)
slot.transferring.add(request)
def finish_transferring(_):
slot.transferring.remove(request)
# 下载完成后调用_process_queue
self._process_queue(spider, slot)
return _
return dfd.addBoth(finish_transferring)
这里也维护了一个下载队列,可根据配置达到延迟下载的要求。真正发起下载请求的是调用了self.handlers.download_request
def download_request(self, request, spider):
# 获取请求的scheme
scheme = urlparse_cached(request).scheme
# 根据scheeme获取下载处理器
handler = self._get_handler(scheme)
if not handler:
raise NotSupported("Unsupported URL scheme '%s': %s" %
(scheme, self._notconfigured[scheme]))
# 开始下载,并返回结果
return handler.download_request(request, spider)
def _get_handler(self, scheme):
# 根据scheme获取对应的下载处理器
# 配置文件中定义好了http、https、ftp等资源的下载处理器
if scheme in self._handlers:
return self._handlers[scheme]
if scheme in self._notconfigured:
return None
if scheme not in self._schemes:
self._notconfigured[scheme] = 'no handler available for that scheme'
return None
path = self._schemes[scheme]
try:
# 实例化下载处理器
dhcls = load_object(path)
dh = dhcls(self._crawler.settings)
except NotConfigured as ex:
self._notconfigured[scheme] = str(ex)
return None
except Exception as ex:
logger.error('Loading "%(clspath)s" for scheme "%(scheme)s"',
{"clspath": path, "scheme": scheme},
exc_info=True, extra={'crawler': self._crawler})
self._notconfigured[scheme] = str(ex)
return None
else:
self._handlers[scheme] = dh
return self._handlers[scheme]
下载前,先通过解析request的scheme来获取对应的下载处理器,默认配置文件中定义的下载处理器:
DOWNLOAD_HANDLERS_BASE = {
'file': 'scrapy.core.downloader.handlers.file.FileDownloadHandler',
'http': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
'https': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
's3': 'scrapy.core.downloader.handlers.s3.S3DownloadHandler',
'ftp': 'scrapy.core.downloader.handlers.ftp.FTPDownloadHandler',
}
然后调用download_request方法,完成网络下载,这里不再详细讲解每个处理器的实现.
在下载过程中,如果发生异常情况,则会依次调用下载器中间件的process_exception方法,每个中间件只需定义自己的异常处理逻辑即可。
如果下载成功,则会依次执行下载器中间件的process_response方法,每个中间件可以进一步处理下载后的结果,最终返回。
拿到最终的下载结果后,再回到ExecuteEngine的_next_request_from_scheduler方法,会看到调用了_handle_downloader_output方法,也就是处理下载结果的逻辑:
def _handle_downloader_output(self, response, request, spider):
# 下载结果必须是Request、Response、Failure其一
assert isinstance(response, (Request, Response, Failure)), response
# 如果是Request,则再次调用crawl,执行Scheduler的入队逻辑
if isinstance(response, Request):
self.crawl(response, spider)
return
# 如果是Response或Failure,则调用scraper的enqueue_scrape进一步处理
# 主要是和Spiders和Pipeline交互
d = self.scraper.enqueue_scrape(response, request, spider)
d.addErrback(lambda f: logger.error('Error while enqueuing downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
return d
拿到下载结果后,主要分2个逻辑,如果是Request实例,则直接再次放入Scheduler请求队列。如果是Response或Failure实例,则调用Scraper的enqueue_scrape方法,进行进一步处理。
Scraper queue for the response
def enqueue_scrape(self, response, request, spider):
# 加入Scrape处理队列
slot = self.slot
dfd = slot.add_response_request(response, request)
def finish_scraping(_):
slot.finish_response(response, request)
self._check_if_closing(spider, slot)
self._scrape_next(spider, slot)
return _
dfd.addBoth(finish_scraping)
dfd.addErrback(
lambda f: logger.error('Scraper bug processing %(request)s',
{'request': request},
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
self._scrape_next(spider, slot)
return dfd
def _scrape_next(self, spider, slot):
while slot.queue:
# 从Scraper队列中获取一个待处理的任务
response, request, deferred = slot.next_response_request_deferred()
self._scrape(response, request, spider).chainDeferred(deferred)
def _scrape(self, response, request, spider):
assert isinstance(response, (Response, Failure))
# 调用_scrape2继续处理
dfd = self._scrape2(response, request, spider)
# 注册异常回调
dfd.addErrback(self.handle_spider_error, request, response, spider)
# 出口回调
dfd.addCallback(self.handle_spider_output, request, response, spider)
return dfd
def _scrape2(self, request_result, request, spider):
# 如果结果不是Failure实例,则调用爬虫中间件管理器的scrape_response
if not isinstance(request_result, Failure):
return self.spidermw.scrape_response(
self.call_spider, request_result, request, spider)
else:
# 直接调用call_spider
dfd = self.call_spider(request_result, request, spider)
return dfd.addErrback(
self._log_download_errors, request_result, request, spider)
首先加入到Scraper的处理队列中,然后从队列中获取到任务,如果不是异常结果,则调用爬虫中间件管理器的scrape_response方法:
def scrape_response(self, scrape_func, response, request, spider):
fname = lambda f:'%s.%s' % (
six.get_method_self(f).__class__.__name__,
six.get_method_function(f).__name__)
def process_spider_input(response):
# 执行一系列爬虫中间件的process_spider_input
for method in self.methods['process_spider_input']:
try:
result = method(response=response, spider=spider)
assert result is None, \
'Middleware %s must returns None or ' \
'raise an exception, got %s ' \
% (fname(method), type(result))
except:
return scrape_func(Failure(), request, spider)
# 执行完中间件的一系列process_spider_input方法后,执行call_spider
return scrape_func(response, request, spider)
def process_spider_exception(_failure):
# 执行一系列爬虫中间件的process_spider_exception
exception = _failure.value
for method in self.methods['process_spider_exception']:
result = method(response=response, exception=exception, spider=spider)
assert result is None or _isiterable(result), \
'Middleware %s must returns None, or an iterable object, got %s ' % \
(fname(method), type(result))
if result is not None:
return result
return _failure
def process_spider_output(result):
# 执行一系列爬虫中间件的process_spider_output
for method in self.methods['process_spider_output']:
result = method(response=response, result=result, spider=spider)
assert _isiterable(result), \
'Middleware %s must returns an iterable object, got %s ' % \
(fname(method), type(result))
return result
# 执行process_spider_input
dfd = mustbe_deferred(process_spider_input, response)
# 注册异常回调
dfd.addErrback(process_spider_exception)
# 注册出口回调
dfd.addCallback(process_spider_output)
return dfd
与上面下载器中间件调用方式非常相似,也调用一系列的前置方法,再执行真正的处理逻辑,然后执行一些列的后置方法。
app spider logic callback
在这里真正的处理逻辑是call_spider,也就是回调我们写的爬虫类:
def call_spider(self, result, request, spider):
# 回调爬虫模块
result.request = request
dfd = defer_result(result)
# 注册回调方法,取得request.callback,如果未定义则调用爬虫模块的parse方法
dfd.addCallbacks(request.callback or spider.parse, request.errback)
return dfd.addCallback(iterate_spider_output)
应用爬虫模块的parse则是第一个回调方法,后续爬虫模块拿到下载结果,可定义下载后的callback就是在这里进行回调执行的。
pipeline processing output
在与爬虫模块交互完成之后,Scraper调用了handle_spider_output方法处理输出结果:
def handle_spider_output(self, result, request, response, spider):
# 处理爬虫输出结果
if not result:
return defer_succeed(None)
it = iter_errback(result, self.handle_spider_error, request, response, spider)
# 注册_process_spidermw_output
dfd = parallel(it, self.concurrent_items,
self._process_spidermw_output, request, response, spider)
return dfd
def _process_spidermw_output(self, output, request, response, spider):
# 处理Spider模块返回的每一个Request/Item
if isinstance(output, Request):
# 如果结果是Request,再次入Scheduler的请求队列
self.crawler.engine.crawl(request=output, spider=spider)
elif isinstance(output, (BaseItem, dict)):
# 如果结果是BaseItem/dict
self.slot.itemproc_size += 1
# 调用Pipeline的process_item
dfd = self.itemproc.process_item(output, spider)
dfd.addBoth(self._itemproc_finished, output, response, spider)
return dfd
elif output is None:
pass
else:
typename = type(output).__name__
logger.error('Spider must return Request, BaseItem, dict or None, '
'got %(typename)r in %(request)s',
{'request': request, 'typename': typename},
extra={'spider': spider})
编写爬虫类时,写的那些回调方法处理逻辑,也就是在这里被回调执行,执行完自定义的解析逻辑后,解析方法可返回新的Request或BaseItem实例,如果是新的请求,则再次通过Scheduler进入请求队列,如果是BaseItem实例,则调用Pipeline管理器,依次执行process_item,也就是我们想输出结果时,只定义Pepeline类,然后重写这个方法就可以了。
ItemPipeManager处理逻辑:
class ItemPipelineManager(MiddlewareManager):
component_name = 'item pipeline'
@classmethod
def _get_mwlist_from_settings(cls, settings):
return build_component_list(settings.getwithbase('ITEM_PIPELINES'))
def _add_middleware(self, pipe):
super(ItemPipelineManager, self)._add_middleware(pipe)
if hasattr(pipe, 'process_item'):
self.methods['process_item'].append(pipe.process_item)
def process_item(self, item, spider):
# 依次调用Pipeline的process_item
return self._process_chain('process_item', item, spider)
可以看到ItemPipeManager也是一个中间件,和之前下载器中间件管理器和爬虫中间件管理器类似,如果子类有定义process_item,则依次执行它 执行完后,调用_itemproc_finished:
def _itemproc_finished(self, output, item, response, spider):
self.slot.itemproc_size -= 1
if isinstance(output, Failure):
ex = output.value
# 如果在Pipeline处理中抛DropItem异常,忽略处理结果
if isinstance(ex, DropItem):
logkws = self.logformatter.dropped(item, ex, response, spider)
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
return self.signals.send_catch_log_deferred(
signal=signals.item_dropped, item=item, response=response,
spider=spider, exception=output.value)
else:
logger.error('Error processing %(item)s', {'item': item},
exc_info=failure_to_exc_info(output),
extra={'spider': spider})
else:
logkws = self.logformatter.scraped(output, response, spider)
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
return self.signals.send_catch_log_deferred(
signal=signals.item_scraped, item=output, response=response,
spider=spider)
这里可以看到,如果想在Pipeline中丢弃某个结果,直接抛出DropItem异常即可,Scrapy会进行对应的处理。
到这里,抓取结果根据自定义的输出类输出到指定位置,而新的Request则会再次进入请求队列,等待引擎下一次调度,也就是再次调用ExecutionEngine的_next_request方法,直至请求队列没有新的任务,整个程序退出。