The Raft Consensus Algorithm
The Raft Consensus Algorithm
Paxos和Raft都是为了实现Consensus一致性这个目标,这个过程如同选举一样,参选者需要说服大多数选民(服务器)投票给他,一旦选定后就跟随其操作。在Raft中,任何时候一个服务器可以扮演下面角色之一:
- Leader: 处理所有客户端交互,日志复制等,一般一次只有一个Leader.
- Follower: 类似选民,完全被动
- Candidate候选人: 类似Proposer律师,可以被选为一个新的领导人。
选举过程
Raft阶段分为两个,首先是选举过程,然后在选举出来的领导人带领进行正常操作,比如日志复制等。下面用图示展示这个过程:
任何一个服务器都可以成为一个候选者Candidate,它向其他服务器Follower发出要求选举自己的请求:
其他服务器同意了,发出OK。
 如果在这个过程中,有一个Follower当机,没有收到请求选举的要求,因此候选者可以自己选自己,只要达到N/2 + 1 的大多数票,候选人还是可以成为Leader的。
如果在这个过程中,有一个Follower当机,没有收到请求选举的要求,因此候选者可以自己选自己,只要达到N/2 + 1 的大多数票,候选人还是可以成为Leader的。这样这个候选者就成为了Leader领导人,它可以向选民也就是Follower们发出指令,比如进行日志复制。
以后通过心跳进行日志复制的通知
如果一旦这个Leader当机崩溃了,那么Follower中有一个成为候选者,发出邀票选举。
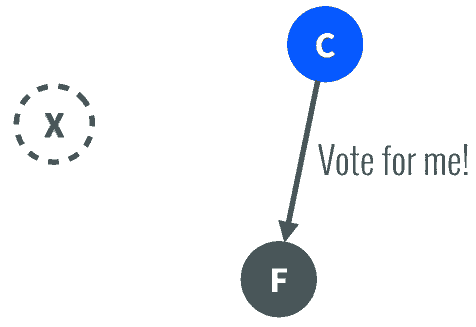
Follower同意后,其成为Leader,继续承担日志复制等指导工作:
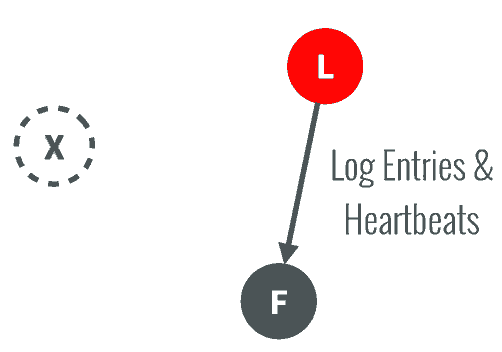
选举说明
自增currentTerm,由Follower转换为Candidate,设置votedFor为自身,并行发起RequestVote RPC,不断重试,直至满足以下任一条件:
- 获得超过半数Server的投票,转换为Leader,广播Heartbeat
- 接收到合法Leader的AppendEntries RPC,转换为Follower
- 选举超时,没有Server选举成功,自增currentTerm,重新选举
细节补充
- Candidate在等待投票结果的过程中,可能会接收到来自其它Leader的AppendEntries RPC。如果该Leader的Term不小于本地的currentTerm,则认可该Leader身份的合法性,主动降级为Follower;反之,则维持Candidate身份,继续等待投票结果
- Candidate既没有选举成功,也没有收到其它Leader的RPC,这种情况一般出现在多个节点同时发起选举(如图Split Vote),最终每个Candidate都将超时。为了减少冲突,这里采取“随机退让”策略,每个Candidate重启选举定时器(随机值),大大降低了冲突概率
日志复制
以日志复制为例子说明Raft算法:
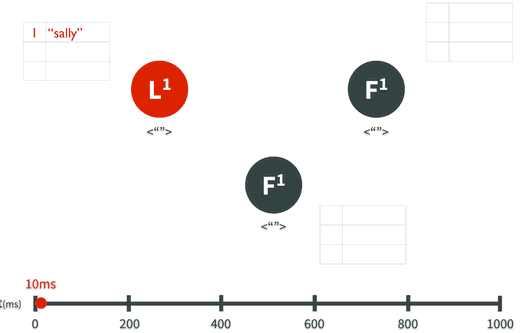
假设Leader领导人已经选出,这时客户端发出增加一个日志的要求,比如日志是”sally”:
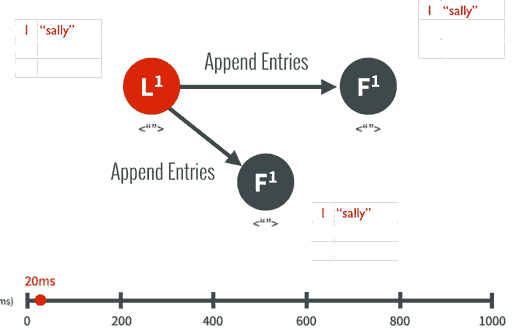
Leader要求Followe遵从他的指令,都将这个新的日志内容追加到他们各自日志中:
大多数follower服务器将日志写入磁盘文件后,确认追加成功,发出Commited Ok:
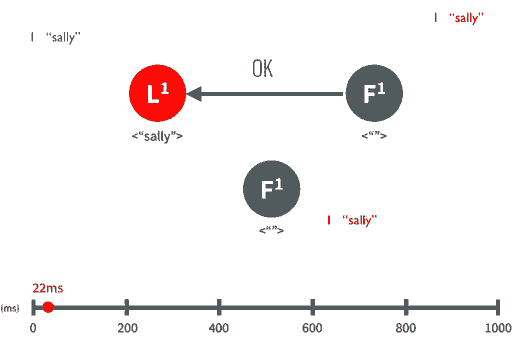
在下一个心跳heartbeat中,Leader会通知所有Follwer更新commited 项目。
对于每个新的日志记录,重复上述过程。
日志复制说明
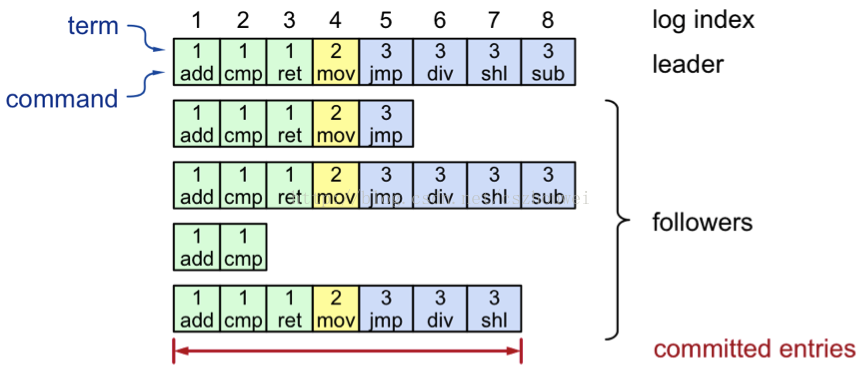
正常操作流程:
- Client发送command给Leader
- Leader追加command至本地log
- Leader广播AppendEntriesRPC至Follower
一旦日志项committed成功:
4.1 Leader应用对应的command至本地StateMachine,并返回结果至Client
4.2 Leader通过后续AppendEntriesRPC将committed日志项通知到Follower
4.3 Follower收到committed日志项后,将其应用至本地StateMachine
网络分区异常
- 如果在这一过程中,发生了网络分区或者网络通信故障,使得Leader不能访问大多数Follwers了,那么Leader只能正常更新它能访问的那些Follower服务器.
- 而大多数的服务器Follower因为没有了Leader,他们重新选举一个候选者作为Leader,然后这个Leader作为代表于外界打交道,如果外界要求其添加新的日志,这个新的Leader就按上述步骤通知大多数Followers
- 如果这时网络故障修复了,那么原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新。
细节补充
当一个新的leader选出来的时候,它的日志和其它的follower的日志可能不一样,这个时候,就需要一个机制来保证日志是一致的。如下图所示,一个新leader产生时,集群状态可能如下:
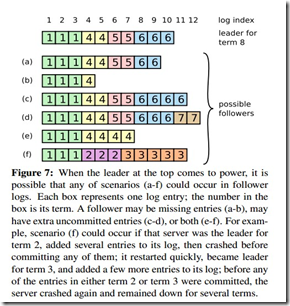
最上面这个是新leader,a~f是follower,每个格子代表一条log entry,格子内的数字代表这个log entry是在哪个term上产生的。
新leader产生后,log就以leader上的log为准。其它的follower要么少了数据比如b,要么多了数据,比如d,要么既少了又多了数据,比如f。
需要有一种机制来让leader和follower对log达成一致:
- leader会为每个follower维护一个nextIndex,表示leader给各个follower发送的下一条log entry在log中的index,初始化为leader的最后一条log entry的下一个位置。
- leader给follower发送AppendEntriesRPC消息,带着(term_id, (nextIndex-1)), term_id即(nextIndex-1)这个槽位的log entry的term_id
- follower接收到AppendEntriesRPC后,会从自己的log中找是不是存在这样的log entry,如果不存在,就给leader回复拒绝消息,然后leader则将nextIndex减1
- 再重复,直到AppendEntriesRPC消息被接收。
以leader和b为例:
- 初始化,nextIndex为11
- leader给b发送AppendEntriesRPC(6,10)
- b在自己log的10号槽位中没有找到term_id为6的log entry。则给leader回应一个拒绝消息。
- 接着,leader将nextIndex减一,变成10,然后给b发送AppendEntriesRPC(6, 9),b在自己log的9号槽位中同样没有找到term_id为6的log entry。循环下去,直到leader发送了AppendEntriesRPC(4,4),b在自己log的槽位4中找到了term_id为4的log entry。接收了消息。
- 随后,leader就可以从槽位5开始给b推送日志了。
animated show
Source code analysis
State Machine in Event Loop
// ________
// --|Snapshot| timeout
// | -------- ______
// recover | ^ | |
// snapshot / | |snapshot | |
// higher | | v | recv majority votes
// term | -------- timeout ----------- -----------
// |-> |Follower| ----------> | Candidate |--------------------> | Leader |
// -------- ----------- -----------
// ^ higher term/ | higher term |
// | new leader | |
// |_______________________|____________________________________ |
func (s *server) loop() {
defer s.debugln("server.loop.end")
state := s.State()
for state != Stopped {
s.debugln("server.loop.run ", state)
switch state {
case Follower:
s.followerLoop()
case Candidate:
s.candidateLoop()
case Leader:
s.leaderLoop()
case Snapshotting:
s.snapshotLoop()
}
state = s.State()
}
}
Log Replication
append entries processing in event loop
// Processes the "append entries" request.
func (s *server) processAppendEntriesRequest(req *AppendEntriesRequest) (*AppendEntriesResponse, bool) {
s.traceln("server.ae.process")
if req.Term < s.currentTerm {
s.debugln("server.ae.error: stale term")
return newAppendEntriesResponse(s.currentTerm, false, s.log.currentIndex(), s.log.CommitIndex()), false
}
if req.Term == s.currentTerm {
_assert(s.State() != Leader, "leader.elected.at.same.term.%d\n", s.currentTerm)
// step-down to follower when it is a candidate
if s.state == Candidate {
// change state to follower
s.setState(Follower)
}
// discover new leader when candidate
// save leader name when follower
s.leader = req.LeaderName
} else {
// Update term and leader.
s.updateCurrentTerm(req.Term, req.LeaderName)
}
// Reject if log doesn't contain a matching previous entry.
if err := s.log.truncate(req.PrevLogIndex, req.PrevLogTerm); err != nil {
s.debugln("server.ae.truncate.error: ", err)
return newAppendEntriesResponse(s.currentTerm, false, s.log.currentIndex(), s.log.CommitIndex()), true
}
// Append entries to the log.
if err := s.log.appendEntries(req.Entries); err != nil {
s.debugln("server.ae.append.error: ", err)
return newAppendEntriesResponse(s.currentTerm, false, s.log.currentIndex(), s.log.CommitIndex()), true
}
// Commit up to the commit index.
if err := s.log.setCommitIndex(req.CommitIndex); err != nil {
s.debugln("server.ae.commit.error: ", err)
return newAppendEntriesResponse(s.currentTerm, false, s.log.currentIndex(), s.log.CommitIndex()), true
}
// once the server appended and committed all the log entries from the leader
return newAppendEntriesResponse(s.currentTerm, true, s.log.currentIndex(), s.log.CommitIndex()), true
}
// Processes the "append entries" response from the peer. This is only
// processed when the server is a leader. Responses received during other
// states are dropped.
func (s *server) processAppendEntriesResponse(resp *AppendEntriesResponse) {
// If we find a higher term then change to a follower and exit.
if resp.Term() > s.Term() {
s.updateCurrentTerm(resp.Term(), "")
return
}
// panic response if it's not successful.
if !resp.Success() {
return
}
// if one peer successfully append a log from the leader term,
// we add it to the synced list
if resp.append == true {
s.syncedPeer[resp.peer] = true
}
// Increment the commit count to make sure we have a quorum before committing.
if len(s.syncedPeer) < s.QuorumSize() {
return
}
// Determine the committed index that a majority has.
var indices []uint64
indices = append(indices, s.log.currentIndex())
for _, peer := range s.peers {
indices = append(indices, peer.getPrevLogIndex())
}
sort.Sort(sort.Reverse(uint64Slice(indices)))
// We can commit up to the index which the majority of the members have appended.
commitIndex := indices[s.QuorumSize()-1]
committedIndex := s.log.commitIndex
if commitIndex > committedIndex {
// leader needs to do a fsync before committing log entries
s.log.sync()
s.log.setCommitIndex(commitIndex)
s.debugln("commit index ", commitIndex)
}
}
append entries processing in heatbeat
//--------------------------------------
// Heartbeat
//--------------------------------------
// The event loop that is run when the server is in a Leader state.
func (s *server) leaderLoop() {
...
// Update the peers prevLogIndex to leader's lastLogIndex and start heartbeat.
for _, peer := range s.peers {
peer.setPrevLogIndex(logIndex)
peer.startHeartbeat()
}
...
}
// Listens to the heartbeat timeout and flushes an AppendEntries RPC.
func (p *Peer) heartbeat(c chan bool) {
...
ticker := time.Tick(p.heartbeatInterval)
debugln("peer.heartbeat: ", p.Name, p.heartbeatInterval)
for {
select {
...
case <-ticker:
start := time.Now()
p.flush()
duration := time.Now().Sub(start)
p.server.DispatchEvent(newEvent(HeartbeatEventType, duration, nil))
}
}
}
func (p *Peer) flush() {
debugln("peer.heartbeat.flush: ", p.Name)
prevLogIndex := p.getPrevLogIndex()
log.Print("heartbeat flush,prev log index is:",prevLogIndex)
term := p.server.currentTerm
// Retrieves a list of entries after a given index as well as the term of the
// index provided. A nil list of entries is returned if the index no longer
// exists because a snapshot was made.
entries, prevLogTerm := p.server.log.getEntriesAfter(prevLogIndex, p.server.maxLogEntriesPerRequest)
if entries != nil {
p.sendAppendEntriesRequest(newAppendEntriesRequest(term, prevLogIndex, prevLogTerm, p.server.log.CommitIndex(), p.server.name, entries))
} else {
p.sendSnapshotRequest(newSnapshotRequest(p.server.name, p.server.snapshot))
}
}
//--------------------------------------
// Append Entries
//--------------------------------------
// Sends an AppendEntries request to the peer through the transport.
func (p *Peer) sendAppendEntriesRequest(req *AppendEntriesRequest) {
tracef("peer.append.send: %s->%s [prevLog:%v length: %v]\n",
p.server.Name(), p.Name, req.PrevLogIndex, len(req.Entries))
resp := p.server.Transporter().SendAppendEntriesRequest(p.server, p, req)
if resp == nil {
p.server.DispatchEvent(newEvent(HeartbeatIntervalEventType, p, nil))
debugln("peer.append.timeout: ", p.server.Name(), "->", p.Name)
return
}
traceln("peer.append.resp: ", p.server.Name(), "<-", p.Name)
p.setLastActivity(time.Now())
// If successful then update the previous log index.
p.Lock()
if resp.Success() {
if len(req.Entries) > 0 {
p.prevLogIndex = req.Entries[len(req.Entries)-1].GetIndex()
}
traceln("peer.append.resp.success: ", p.Name, "; idx =", p.prevLogIndex)
} else {
if resp.Term() > p.server.Term() {
// this happens when there is a new leader comes up that this *leader* has not
// known yet.
// this server can know until the new leader send a ae with higher term
// or this server finish processing this response.
debugln("peer.append.resp.not.update: new.leader.found")
} else if resp.Term() == req.Term && resp.CommitIndex() >= p.prevLogIndex {
// we may miss a response from peer
// so maybe the peer has committed the logs we just sent
// but we did not receive the successful reply and did not increase
// the prevLogIndex
// peer failed to truncate the log and sent a fail reply at this time
// we just need to update peer's prevLog index to commitIndex
p.prevLogIndex = resp.CommitIndex()
debugln("peer.append.resp.update: ", p.Name, "; idx =", p.prevLogIndex)
} else if p.prevLogIndex > 0 {
// If it was unsuccessful then decrement the previous log index and
// we'll try again next time.
// Decrement the previous log index down until we find a match. Don't
// let it go below where the peer's commit index is though. That's a
// problem.
p.prevLogIndex--
// if it is not enough, we directly decrease to the index of the peer log
if p.prevLogIndex > resp.Index() {
p.prevLogIndex = resp.Index()
}
debugln("peer.append.resp.decrement: ", p.Name, "; idx =", p.prevLogIndex)
}
}
p.Unlock()
// Attach the peer to resp, thus server can know where it comes from
resp.peer = p.Name
// Send response to server for processing.
p.server.sendAsync(resp)
}