BoltDB In-depth Analysis
boltdb in-depth analysis
BoltDB中的Bucket类似于传统关系型数据库的”表”。BoltDB通过Bucket将一个庞大的数据库划分成诸多的命名空间。用户在每个命名空间内存储KV数据,通过此种办法可以提高数据的搜索效率。
例如,一个BoltDB中可:
创建User Bucket,用于记录用户信息(存储的K是用户名,而Value是用户详情)
创建Order Bucket,用户记录用户订单信息(存储的K是用户名,而Value则是订单详情)
……
与传统关系型数据库中的表所不同的是,Bucket是一种嵌套型的结构。传统关系型数据库如Mysql中表下无法再创建子表,而BoltDB中的Bucket可以创建子Bucket.
Inline Bucket
Bucket本质上属于一个逻辑概念。Bucket里面存储的都是Key/Value记录。BoltDB中创建的每个Bucket也会作为一个KV记录被持久化存储在数据文件中。为了提高查询效率,BoltDB对Bucket的存储结构作了一定优化,对于容量不大的Bucket进行inline存储:即将Bucket内的KV记录与Bucket的KV记录连续存放。这样做的好处显而易见:搜寻到了Bucket,即可遍历出该Bucket下的所有KV记录。但是也不能将Bucket都以Inline方式存储,当一个Bucket下的KV记录数超过一定限制时,便不再适合这种方式存储。
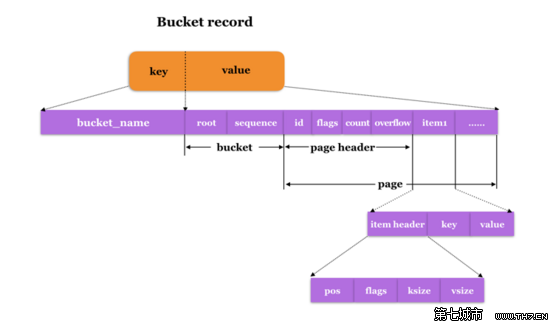
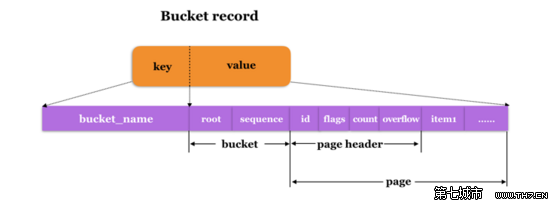
Inline Bucket在磁盘上的存储结构如下图所示:
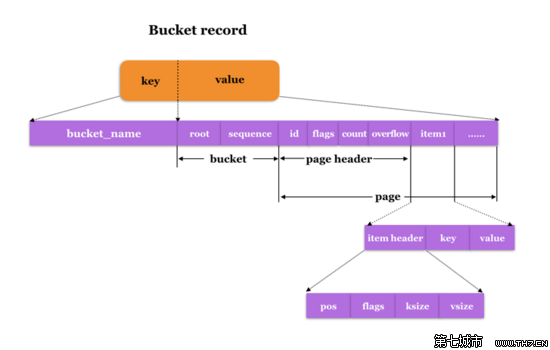
- key: 存储Bucket name
- value: 存放bucket value,对于inline bucket,其value包含 bucket header{root, sequence},以及bucket body,bucket body是一个模拟的page,包含page header,以及page body,page body中记录该Bucket内创建的所有sub Bucket以及普通的KV记录,每个KV记录对应一个item。
Bucket存储
Bucket是BoltDB内划分命名空间的基础。所有的KV记录都必须被存储在某个Bucket之下。而Bucket在BoltDB内其实也只是一个普通的KV记录而已。
Bucket的内存数据结构
// Bucket represents a collection of key/value pairs inside the database.
type Bucket struct {
*bucket
tx *Tx // the associated transaction
buckets map[string]*Bucket // subbucket cache
page *page // inline page reference
rootNode *node // materialized node for the root page.
nodes map[pgid]*node // node cache
// Sets the threshold for filling nodes when they split. By default,
// the bucket will fill to 50% but it can be useful to increase this
// amount if you know that your write workloads are mostly append-only.
//
// This is non-persisted across transactions so it must be set in every Tx.
FillPercent float64
}
- bucket:Bucket的磁盘描述结构
- buckets: Bucket的孩子Bucket,每个Bucket下可创建子Bucket
- page: Bucket的Inline page引用
- rootNode: Bucket的root page的内存节点
- nodes: node的cache
这其中有几个成员值得详细一说:
- page: 对于存储KV数量不多的Bucket,其KV记录会与Bucket记录连续存放,这种Bucket被称为Inline Bucket。而每个Bucket需要记录其内存储KV的引用,对于Inline Bucket,其page指向的是Bucket后的连续地址空间.
type page struct {
id pgid
flags uint16
count uint16
overflow uint32
ptr uintptr
}
- bucket:Bucket在磁盘上的存储KV记录的Value部分的头部。对于Inline Bucket,其内创建的KV记录存储在bucket之后的page,而这个page(fake page)在物理位置上与bucket是连续存放的。
// bucket represents the on-file representation of a bucket.
// This is stored as the "value" of a bucket key. If the bucket is small enough,
// then its root page can be stored inline in the "value", after the bucket
// header. In the case of inline buckets, the "root" will be 0.
type bucket struct {
root pgid // page id of the bucket's root-level page
sequence uint64 // monotonically incrementing, used by NextSequence()
}
// node represents an in-memory, deserialized page.
type node struct {
bucket *Bucket
isLeaf bool
unbalanced bool
spilled bool
key []byte
pgid pgid
parent *node
children nodes
inodes inodes
}
type inodes []inode
// inode represents an internal node inside of a node.
// It can be used to point to elements in a page or point
// to an element which hasn't been added to a page yet.
type inode struct {
flags uint32
pgid pgid
key []byte
value []byte
}
Root Bucket Init
BoltDB中的Bucket是一个嵌套结构,因此,系统中必然存在一个root bucket。用户创建的所有Bucket都是该Bucket的子孙。Root Bucket在DB被初次创建的时候而创建的。DB被创建时会写入一系列系统元数据,其中就包括root bucket信息,这些元数据被存储在BoltDB专门的meta page中,如下:
// init creates a new database file and initializes its meta pages.
func (db *DB) init() error {
// Set the page size to the OS page size.
db.pageSize = os.Getpagesize()
// Create two meta pages on a buffer.
buf := make([]byte, db.pageSize*4)
for i := 0; i < 2; i++ {
p := db.pageInBuffer(buf[:], pgid(i))
p.id = pgid(i)
p.flags = metaPageFlag
// Initialize the meta page.
m := p.meta()
m.magic = magic
m.version = version
m.pageSize = uint32(db.pageSize)
m.freelist = 2
m.root = bucket{root: 3}
m.pgid = 4
m.txid = txid(i)
m.checksum = m.sum64()
}
// Write an empty freelist at page 3.
p := db.pageInBuffer(buf[:], pgid(2))
p.id = pgid(2)
p.flags = freelistPageFlag
p.count = 0
// Write an empty leaf page at page 4.
p = db.pageInBuffer(buf[:], pgid(3))
p.id = pgid(3)
p.flags = leafPageFlag
p.count = 0
// Write the buffer to our data file.
if _, err := db.ops.writeAt(buf, 0); err != nil {
return err
}
if err := fdatasync(db); err != nil {
return err
}
return nil
}
从上面的BoltDB初始化过程可以发现,系统root Bucket的page id是3,意味着在root bucket下创建子Bucket的话,子Bucket的记录一定会写入page 3。
创建Bucket流程
我们这里以两种情形来说明如何创建Bucket:在root Bucket下创建Bucket和在非root Bucket下创建Bucket。
root Bucket下创建Bucket
无论是哪种方式Bucket,创建Bucket的第一步都是定位到父Bucket所在地(Bucket存储所在的page)。而我们前面说过,root Bucket的起始page id为3。 因此,在root Bucket创建sub Bucket的第一步便是在page 3上搜索Bucket应当的插入位置。
// CreateBucket creates a new bucket at the given key and returns the new bucket.
// Returns an error if the key already exists, if the bucket name is blank, or if the bucket name is too long.
// The bucket instance is only valid for the lifetime of the transaction.
func (b *Bucket) CreateBucket(key []byte) (*Bucket, error) {
if b.tx.db == nil {
return nil, ErrTxClosed
} else if !b.tx.writable {
return nil, ErrTxNotWritable
} else if len(key) == 0 {
return nil, ErrBucketNameRequired
}
// Move cursor to correct position.
c := b.Cursor()
k, _, flags := c.seek(key)
// Return an error if there is an existing key.
if bytes.Equal(key, k) {
if (flags & bucketLeafFlag) != 0 {
return nil, ErrBucketExists
}
return nil, ErrIncompatibleValue
}
// Create empty, inline bucket.
var bucket = Bucket{
bucket: &bucket{},
rootNode: &node{isLeaf: true},
FillPercent: DefaultFillPercent,
}
var value = bucket.write()
// Insert into node.
key = cloneBytes(key)
c.node().put(key, key, value, 0, bucketLeafFlag)
// Since subbuckets are not allowed on inline buckets, we need to
// dereference the inline page, if it exists. This will cause the bucket
// to be treated as a regular, non-inline bucket for the rest of the tx.
b.page = nil
return b.Bucket(key), nil
}
上述过程看起来非常简单:
为父Bucket(也就是root Bucket)创建Cursor,并定位子Bucket的位置; 创建一个Bucket,当然,起始的时候肯定是一个Inline Bucket; 将2创建的Bucket写入到1中Cursor定位的地方 然后此事就算了结了 Cursor其实只是保存了查找过程中的搜索路径而已。类似一个stack,栈底是搜索路径的起点,栈顶是搜索路径的终点。Cursor.seek(key)完成后,Cursor中就已经记录了到key的搜索路径。
第一次创建Bucket之前,root Bucket所在的page 3此时空无一物。
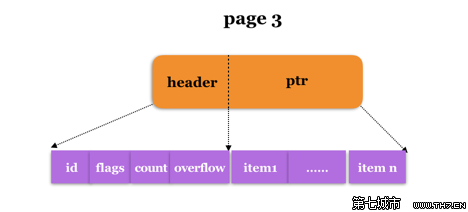
显然我们第一个创建的Bucket会落在item1的位置。于是,page 3的内容变成了如下所示:
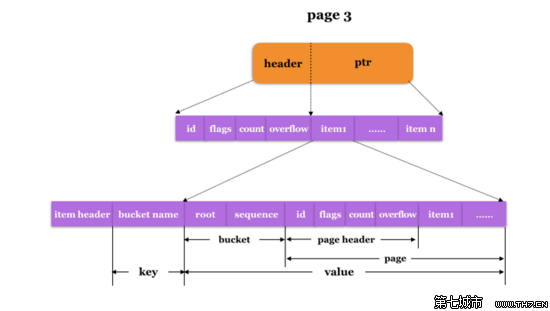
那么,root Bucket下的第一个Bucket算是正式创建成功,接下来要做的就是向该Bucket内插入KV记录了。
已有Bucket下创建Bucket
前面描述过了在root Bucket下创建Bucket的过程,这里我们再来研究下如何在已经创建过的Bucket下创建子Bucket的过程。在现有Bucket下创建子Bucket与root下创建Bucket的过程其实是一样的,因为代码用的都是同一套。它们的区别在于搜寻的路径不一样,在root Bucket下创建Bucket是从root page(page 3)开始,而在现有Bucket下创建子Bucket则搜寻路径是从该Bucket的rootNode开始的。
在已有Bucket下面创建新Bucket的话,第一步是打开该已有的Bucket,填充该父Bucket的一些信息,然后在该父Bucket下创建子Bucket,我们先来看看怎么打开一个Bucket。
// Bucket retrieves a nested bucket by name.
// Returns nil if the bucket does not exist.
// The bucket instance is only valid for the lifetime of the transaction.
func (b *Bucket) Bucket(name []byte) *Bucket {
if b.buckets != nil {
if child := b.buckets[string(name)]; child != nil {
return child
}
}
// Move cursor to key.
c := b.Cursor()
k, v, flags := c.seek(name)
// Return nil if the key doesn't exist or it is not a bucket.
if !bytes.Equal(name, k) || (flags&bucketLeafFlag) == 0 {
return nil
}
// Otherwise create a bucket and cache it.
var child = b.openBucket(v)
if b.buckets != nil {
b.buckets[string(name)] = child
}
return child
}
这里首先是在root Bucket下查找该Bucket的KV记录,注意这里的Bucket还是一个Inline Bucket,因此其value包含了一大坨内容,这个在前面已经详细描述过,我们再来复习下,对于一个Inline Bucket,其KV内容如下:
好,那接下来就是openBucket啦:
// Helper method that re-interprets a sub-bucket value
// from a parent into a Bucket
func (b *Bucket) openBucket(value []byte) *Bucket {
var child = newBucket(b.tx)
// If unaligned load/stores are broken on this arch and value is
// unaligned simply clone to an aligned byte array.
unaligned := brokenUnaligned && uintptr(unsafe.Pointer(&value[0]))&3 != 0
if unaligned {
value = cloneBytes(value)
}
// If this is a writable transaction then we need to copy the bucket entry.
// Read-only transactions can point directly at the mmap entry.
if b.tx.writable && !unaligned {
child.bucket = &bucket{}
*child.bucket = *(*bucket)(unsafe.Pointer(&value[0]))
} else {
child.bucket = (*bucket)(unsafe.Pointer(&value[0]))
}
// Save a reference to the inline page if the bucket is inline.
if child.root == 0 {
child.page = (*page)(unsafe.Pointer(&value[bucketHeaderSize]))
}
return &child
}
对于Inline Bucket,child.root肯定是0,因此,child.page就是Bucket value的bucket之后的内容,这其实是一个模拟的page。这样,Bucket被打开了,其root以及page也被正确初始化了。接下来就可以在Bucket下创建孩子Bucket了。
现在父Bucket也打开了,我们继续刚刚的话题,在父Bucket下创建子Bucket,与在root Bucket下创建子Bucket流程类似,只是这一次,我们搜索路径的起点是父Bucket.root,由于父Bucket是一个Inline Bucket,父Bucket.root是0,在搜索的时候便是从rootNode开始,如下:
// seek moves the cursor to a given key and returns it.
// If the key does not exist then the next key is used.
func (c *Cursor) seek(seek []byte) (key []byte, value []byte, flags uint32) {
_assert(c.bucket.tx.db != nil, "tx closed")
// Start from root page/node and traverse to correct page.
c.stack = c.stack[:0]
c.search(seek, c.bucket.root)
ref := &c.stack[len(c.stack)-1]
// If the cursor is pointing to the end of page/node then return nil.
if ref.index >= ref.count() {
return nil, nil, 0
}
// If this is a bucket then return a nil value.
return c.keyValue()
}
// search recursively performs a binary search against a given page/node until it finds a given key.
func (c *Cursor) search(key []byte, pgid pgid) {
p, n := c.bucket.pageNode(pgid)
if p != nil && (p.flags&(branchPageFlag|leafPageFlag)) == 0 {
panic(fmt.Sprintf("invalid page type: %d: %x", p.id, p.flags))
}
e := elemRef{page: p, node: n}
c.stack = append(c.stack, e)
// If we're on a leaf page/node then find the specific node.
if e.isLeaf() {
c.nsearch(key)
return
}
if n != nil {
c.searchNode(key, n)
return
}
c.searchPage(key, p)
}
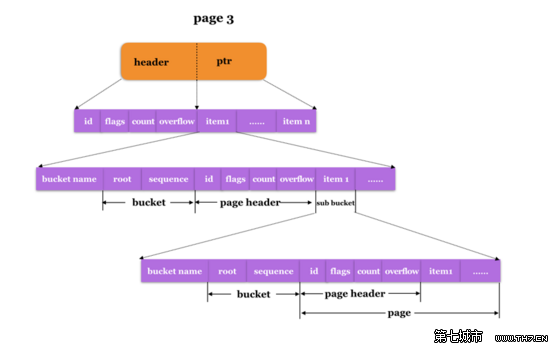
从上面看到,对于Inline Bucket,其搜索路径的起点是Bucket.page,这是在Bucket在Open的时候被加载并初始化的,我们已经在前面仔细描述过。好,到这里我们开始从Bucket.page开始搜索,假如已经找到了子Bucket应该存储的位置,其实就是父Bucket的page内的第一项,将子Bucket的内容(KV)写入以后,磁盘上的存储结构就变成了下面这样:
Bucket内插入KV
Bucket内插入KV与我们上面说的Bucket下创建子Bucket逻辑几无二致,只是插入的记录的数据格式不同罢了,插入子Bucket的时候我们还需要给这个子Bucket分配一个BucketHeader等等,比较复杂。写入普通KV记录看起来就简单了许多,其流程是先搜寻到记录应该插入的位置,然后将KV记录插入在该位置,这与创建Bucket流程没什么不同:
// Put sets the value for a key in the bucket.
// If the key exist then its previous value will be overwritten.
// Supplied value must remain valid for the life of the transaction.
// Returns an error if the bucket was created from a read-only transaction, if the key is blank, if the key is too large, or if the value is too large.
func (b *Bucket) Put(key []byte, value []byte) error {
if b.tx.db == nil {
return ErrTxClosed
} else if !b.Writable() {
return ErrTxNotWritable
} else if len(key) == 0 {
return ErrKeyRequired
} else if len(key) > MaxKeySize {
return ErrKeyTooLarge
} else if int64(len(value)) > MaxValueSize {
return ErrValueTooLarge
}
// Move cursor to correct position.
c := b.Cursor()
k, _, flags := c.seek(key)
// Return an error if there is an existing key with a bucket value.
if bytes.Equal(key, k) && (flags&bucketLeafFlag) != 0 {
return ErrIncompatibleValue
}
// Insert into node.
key = cloneBytes(key)
c.node().put(key, key, value, 0, 0)
return nil
}
在bucket内插入普通KV记录后,其内部存储结构如下所示:(注意:我们说的还是Inline Bucket哦)