leaf&&gonet2&&pomelo
game server frameworks like leaf&&gonet2&&pomelo
Leaf 游戏服务器框架简介
Leaf 是一个由 Go 语言(golang)编写的开发效率和执行效率并重的开源游戏服务器框架。Leaf 适用于各类游戏服务器的开发,包括 H5(HTML5)游戏服务器。
Leaf 的关注点:
- 良好的使用体验。Leaf 总是尽可能的提供简洁和易用的接口,尽可能的提升开发的效率
- 稳定性。Leaf 总是尽可能的恢复运行过程中的错误,避免崩溃
- 多核支持。Leaf 通过模块机制和 leaf/go 尽可能的利用多核资源,同时又尽量避免各种副作用
- 模块机制。
Leaf 的模块机制
一个 Leaf 开发的游戏服务器由多个模块组成(例如 LeafServer),模块有以下特点:
- 每个模块运行在一个单独的 goroutine 中
- 模块间通过一套轻量的 RPC 机制通讯(leaf/chanrpc)
Leaf 不建议在游戏服务器中设计过多的模块。
游戏服务器在启动时进行模块的注册,例如:
leaf.Run(
game.Module,
gate.Module,
login.Module,
)
这里按顺序注册了 game、gate、login 三个模块。每个模块都需要实现接口:
type Module interface {
OnInit()
OnDestroy()
Run(closeSig chan bool)
}
Leaf 首先会在同一个 goroutine 中按模块注册顺序执行模块的 OnInit 方法,等到所有模块 OnInit 方法执行完成后则为每一个模块启动一个 goroutine 并执行模块的 Run 方法。最后,游戏服务器关闭时(Ctrl + C 关闭游戏服务器)将按模块注册相反顺序在同一个 goroutine 中执行模块的 OnDestroy 方法。
Leaf 源码概览
- leaf/chanrpc 提供了一套基于 channel 的 RPC 机制,用于游戏服务器模块间通讯
- leaf/db 数据库相关,目前支持 MongoDB
- leaf/gate 网关模块,负责游戏客户端的接入
- leaf/go 用于创建能够被 Leaf 管理的 goroutine
- leaf/log 日志相关
- leaf/network 网络相关,使用 TCP 和 WebSocket 协议,可自定义消息格式,默认 Leaf 提供了基于 protobuf 和 JSON 的消息格式
- leaf/recordfile 用于管理游戏数据
- leaf/timer 定时器相关
- leaf/util 辅助库
使用 Leaf 开发游戏服务器
LeafServer 是一个基于 Leaf 开发的游戏服务器,我们以 LeafServer 作为起点。
获取 LeafServer:
git clone https://github.com/name5566/leafserver
设置 leafserver 目录到 GOPATH 环境变量后获取 Leaf:
go get github.com/name5566/leaf
编译 LeafServer:
go install server
如果一切顺利,运行 server 你可以获得以下输出:
2015/08/26 22:11:27 [release] Leaf 1.1.2 starting up
敲击 Ctrl + C 关闭游戏服务器,服务器正常关闭输出:
2015/08/26 22:12:30 [release] Leaf closing down (signal: interrupt)
Hello Leaf
现在,在 LeafServer 的基础上,我们来看看游戏服务器如何接收和处理网络消息。
首先定义一个 JSON 格式的消息(protobuf 类似)。打开 LeafServer msg/msg.go 文件可以看到如下代码:
package msg
import (
"github.com/name5566/leaf/network"
)
var Processor network.Processor
func init() {
}
Processor 为消息的处理器(可由用户自定义),这里我们使用 Leaf 默认提供的 JSON 消息处理器并尝试添加一个名字为 Hello 的消息:
package msg
import (
"github.com/name5566/leaf/network/json"
)
// 使用默认的 JSON 消息处理器(默认还提供了 protobuf 消息处理器)
var Processor = json.NewProcessor()
func init() {
// 这里我们注册了一个 JSON 消息 Hello
Processor.Register(&Hello{})
}
// 一个结构体定义了一个 JSON 消息的格式
// 消息名为 Hello
type Hello struct {
Name string
}
客户端发送到游戏服务器的消息需要通过 gate 模块路由,简而言之,gate 模块决定了某个消息具体交给内部的哪个模块来处理。这里,我们将 Hello 消息路由到 game 模块中。打开 LeafServer gate/router.go,敲入如下代码:
package gate
import (
"server/game"
"server/msg"
)
func init() {
// 这里指定消息 Hello 路由到 game 模块
// 模块间使用 ChanRPC 通讯,消息路由也不例外
msg.Processor.SetRouter(&msg.Hello{}, game.ChanRPC)
}
一切就绪,我们现在可以在 game 模块中处理 Hello 消息了。打开 LeafServer game/internal/handler.go,敲入如下代码:
package internal
import (
"github.com/name5566/leaf/log"
"github.com/name5566/leaf/gate"
"reflect"
"server/msg"
)
func init() {
// 向当前模块(game 模块)注册 Hello 消息的消息处理函数 handleHello
handler(&msg.Hello{}, handleHello)
}
func handler(m interface{}, h interface{}) {
skeleton.RegisterChanRPC(reflect.TypeOf(m), h)
}
func handleHello(args []interface{}) {
// 收到的 Hello 消息
m := args[0].(*msg.Hello)
// 消息的发送者
a := args[1].(gate.Agent)
// 输出收到的消息的内容
log.Debug("hello %v", m.Name)
// 给发送者回应一个 Hello 消息
a.WriteMsg(&msg.Hello{
Name: "client",
})
}
到这里,一个简单的范例就完成了。为了更加清楚的了解消息的格式,我们从 0 编写一个最简单的测试客户端。
Leaf 中,当选择使用 TCP 协议时,在网络中传输的消息都会使用以下格式:
--------------
| len | data |
--------------
其中:
- len 表示了 data 部分的长度(字节数)。len 本身也有长度,默认为 2 字节(可配置),len 本身的长度决定了单个消息的最大大小
- data 部分使用 JSON 或者 protobuf 编码(也可自定义其他编码方式)
测试客户端同样使用 Go 语言编写:
package main
import (
"encoding/binary"
"net"
)
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:3563")
if err != nil {
panic(err)
}
// Hello 消息(JSON 格式)
// 对应游戏服务器 Hello 消息结构体
data := []byte(`{
"Hello": {
"Name": "leaf"
}
}`)
// len + data
m := make([]byte, 2+len(data))
// 默认使用大端序
binary.BigEndian.PutUint16(m, uint16(len(data)))
copy(m[2:], data)
// 发送消息
conn.Write(m)
}
执行此测试客户端,游戏服务器输出:
2015/09/25 07:41:03 [debug ] hello leaf
2015/09/25 07:41:03 [debug ] read message: read tcp 127.0.0.1:3563->127.0.0.1:54599: wsarecv: An existing connection was forcibly closed by the remote host.
测试客户端发送完消息以后就退出了,此时和游戏服务器的连接断开,相应的,游戏服务器输出连接断开的提示日志(第二条日志,日志的具体内容和 Go 语言版本有关)。
除了使用 TCP 协议外,还可以选择使用 WebSocket 协议(例如开发 H5 游戏)。Leaf 可以单独使用 TCP 协议或 WebSocket 协议,也可以同时使用两者,换而言之,服务器可以同时接受 TCP 连接和 WebSocket 连接,对开发者而言消息来自 TCP 还是 WebSocket 是完全透明的。现在,我们来编写一个对应上例的使用 WebSocket 协议的客户端:
<script type="text/javascript">
var ws = new WebSocket('ws://127.0.0.1:3653')
ws.onopen = function() {
// 发送 Hello 消息
ws.send(JSON.stringify({Hello: {
Name: 'leaf'
}}))
}
</script>
保存上述代码到某 HTML 文件中并使用(任意支持 WebSocket 协议的)浏览器打开。在打开此 HTML 文件前,首先需要配置一下 LeafServer 的 bin/conf/server.json 文件,增加 WebSocket 监听地址(WSAddr):
{
"LogLevel": "debug",
"LogPath": "",
"TCPAddr": "127.0.0.1:3563",
"WSAddr": "127.0.0.1:3653",
"MaxConnNum": 20000
}
重启游戏服务器后,方可接受 WebSocket 消息:
2015/09/25 07:50:03 [debug ] hello leaf
在 Leaf 中使用 WebSocket 需要注意的一点是:Leaf 总是发送二进制消息而非文本消息。
Leaf 模块详解
LeafServer 中包含了 3 个模块,它们分别是:
- gate 模块,负责游戏客户端的接入
- login 模块,负责登录流程
- game 模块,负责游戏主逻辑
一般来说(而非强制规定),从代码结构上,一个 Leaf 模块:
- 放置于一个目录中(例如 game 模块放置于 game 目录中)
- 模块的具体实现放置于 internal 包中(例如 game 模块的具体实现放置于 game/internal 包中)
每个模块下一般有一个 external.go 的文件,顾名思义表示模块对外暴露的接口,这里以 game 模块的 external.go 文件为例:
package game
import (
"server/game/internal"
)
var (
// 实例化 game 模块
Module = new(internal.Module)
// 暴露 ChanRPC
ChanRPC = internal.ChanRPC
)
首先,模块会被实例化,这样才能注册到 Leaf 框架中(详见 LeafServer main.go),另外,模块暴露的 ChanRPC 被用于模块间通讯。
进入 game 模块的内部(LeafServer game/internal/module.go):
package internal
import (
"github.com/name5566/leaf/module"
"server/base"
)
var (
skeleton = base.NewSkeleton()
ChanRPC = skeleton.ChanRPCServer
)
type Module struct {
*module.Skeleton
}
func (m *Module) OnInit() {
m.Skeleton = skeleton
}
func (m *Module) OnDestroy() {
}
模块中最关键的就是 skeleton(骨架),skeleton 实现了 Module 接口的 Run 方法并提供了:
- ChanRPC
- goroutine
- 定时器
Leaf ChanRPC
由于 Leaf 中,每个模块跑在独立的 goroutine 上,为了模块间方便的相互调用就有了基于 channel 的 RPC 机制。一个 ChanRPC 需要在游戏服务器初始化的时候进行注册(注册过程不是 goroutine 安全的),例如 LeafServer 中 game 模块注册了 NewAgent 和 CloseAgent 两个 ChanRPC:
package internal
import (
"github.com/name5566/leaf/gate"
)
func init() {
skeleton.RegisterChanRPC("NewAgent", rpcNewAgent)
skeleton.RegisterChanRPC("CloseAgent", rpcCloseAgent)
}
func rpcNewAgent(args []interface{}) {
}
func rpcCloseAgent(args []interface{}) {
}
使用 skeleton 来注册 ChanRPC。RegisterChanRPC 的第一个参数是 ChanRPC 的名字,第二个参数是 ChanRPC 的实现。这里的 NewAgent 和 CloseAgent 会被 LeafServer 的 gate 模块在连接建立和连接中断时调用。ChanRPC 的调用方有 3 种调用模式:
- 同步模式,调用并等待 ChanRPC 返回
- 异步模式,调用并提供回调函数,回调函数会在 ChanRPC 返回后被调用
- Go 模式,调用并立即返回,忽略任何返回值和错误
gate 模块这样调用 game 模块的 NewAgent ChanRPC(这仅仅是一个示例,实际的代码细节复杂的多):
game.ChanRPC.Go("NewAgent", a)
这里调用 NewAgent 并传递参数 a,我们在 rpcNewAgent 的参数 args[0] 中可以取到 a(args[1] 表示第二个参数,以此类推)。
更加详细的用法可以参考 leaf/chanrpc。需要注意的是,无论封装多么精巧,跨 goroutine 的调用总不能像直接的函数调用那样简单直接,因此除非必要我们不要构建太多的模块,模块间不要太频繁的交互。模块在 Leaf 中被设计出来最主要是用于划分功能而非利用多核,Leaf 认为在模块内按需使用 goroutine 才是多核利用率问题的解决之道。
Leaf Go
善用 goroutine 能够充分利用多核资源,Leaf 提供的 Go 机制解决了原生 goroutine 存在的一些问题:
- 能够恢复 goroutine 运行过程中的错误
- 游戏服务器会等待所有 goroutine 执行结束后才关闭
- 非常方便的获取 goroutine 执行的结果数据
- 在一些特殊场合保证 goroutine 按创建顺序执行
我们来看一个例子(可以在 LeafServer 的模块的 OnInit 方法中测试):
log.Debug("1")
// 定义变量 res 接收结果
var res string
skeleton.Go(func() {
// 这里使用 Sleep 来模拟一个很慢的操作
time.Sleep(1 * time.Second)
// 假定得到结果
res = "3"
}, func() {
log.Debug(res)
})
log.Debug("2")
上面代码执行结果如下:
2015/08/27 20:37:17 [debug ] 1
2015/08/27 20:37:17 [debug ] 2
2015/08/27 20:37:18 [debug ] 3
这里的 Go 方法接收 2 个函数作为参数,第一个函数会被放置在一个新创建的 goroutine 中执行,在其执行完成之后,第二个函数会在当前 goroutine 中被执行。由此,我们可以看到变量 res 同一时刻总是只被一个 goroutine 访问,这就避免了同步机制的使用。Go 的设计使得 CPU 得到充分利用,避免操作阻塞当前 goroutine,同时又无需为共享资源同步而忧心。
更加详细的用法可以参考 leaf/go。
Leaf timer
Go 语言标准库提供了定时器的支持:
func AfterFunc(d Duration, f func()) *Timer
AfterFunc 会等待 d 时长后调用 f 函数,这里的 f 函数将在另外一个 goroutine 中执行。Leaf 提供了一个相同的 AfterFunc 函数,相比之下,f 函数在 AfterFunc 的调用 goroutine 中执行,这样就避免了同步机制的使用:
skeleton.AfterFunc(5 * time.Second, func() {
// ...
})
另外,Leaf timer 还支持 cron 表达式,用于实现诸如“每天 9 点执行”、“每周末 6 点执行”的逻辑。
更加详细的用法可以参考 leaf/timer。
Leaf log
Leaf 的 log 系统支持多种日志级别:
- Debug 日志,非关键日志
- Release 日志,关键日志
- Error 日志,错误日志
- Fatal 日志,致命错误日志
Debug < Release < Error < Fatal(日志级别高低)
在 LeafServer 中,bin/conf/server.json 可以配置日志级别,低于配置的日志级别的日志将不会输出。Fatal 日志比较特殊,每次输出 Fatal 日志之后游戏服务器进程就会结束,通常来说,只在游戏服务器初始化失败时使用 Fatal 日志。
更加详细的用法可以参考 leaf/log。
Leaf recordfile
Leaf 的 recordfile 是基于 CSV 格式(范例见这里)。recordfile 用于管理游戏配置数据。在 LeafServer 中使用 recordfile 非常简单:
- 将 CSV 文件放置于 bin/gamedata 目录中
- 在 gamedata 模块中调用函数 readRf 读取 CSV 文件
范例:
// 确保 bin/gamedata 目录中存在 Test.txt 文件
// 文件名必须和此结构体名称相同(大小写敏感)
// 结构体的一个实例映射 recordfile 中的一行
type Test struct {
// 将第一列按 int 类型解析
// "index" 表明在此列上建立唯一索引
Id int "index"
// 将第二列解析为长度为 4 的整型数组
Arr [4]int
// 将第三列解析为字符串
Str string
}
// 读取 recordfile Test.txt 到内存中
// RfTest 即为 Test.txt 的内存镜像
var RfTest = readRf(Test{})
func init() {
// 按索引查找
// 获取 Test.txt 中 Id 为 1 的那一行
r := RfTest.Index(1)
if r != nil {
row := r.(*Test)
// 输出此行的所有列的数据
log.Debug("%v %v %v", row.Id, row.Arr, row.Str)
}
}
更加详细的用法可以参考 leaf/recordfile。
了解更多
阅读 Wiki 获取更多的帮助:https://github.com/name5566/leaf/wiki
gonet2
gonet/2是新一代游戏服务器骨架,基于go语言开发,采用了先进的http/2作为服务器端主要通信协议,以microservice作为主要思想进行架构,采用docker作为服务发布手段。相比第一代gonet,基础技术选型更加先进,结构更加清晰易读可扩展。
相关文档
- INSTALL.md – 安装
- CICD.md – 持续集成与持续部署
为什么用microservice架构?
业务分离是游戏服务器架构的基本思路,通过职能划分,能够更加合理的调配服务器资源。 资源的大分类包括,IO,CPU,MEM,BANDWIDTH, 例如常见的情景:
IO: 如: 数据库,文件服务,消耗大量读写
CPU: 如: 游戏逻辑,消耗大量指令
MEM: 如: 分词,排名,pubsub, 消耗大量内存
BANDWIDTH: 内网带宽高,外网带宽低,物理上越接近的,传输速度越高
玩家对每种服务的请求量有巨大的不同,比如逻辑请求100次,分词请求1次,所以,没有必要1:1配置资源,通过microservice方式分离服务,可以根据业务使用情况,按需配置服务器资源。当服务容量增长,如果在monolithic的架构上做,即全部服务揉在一起成一个大进程,会严重浪费资源,比如大量内存被极少被使用的模块占用, 更严重的问题是,单台服务器的资源不是无限制的,虽然目前顶级配置的服务器可以安装高达96GB的内存,但也极其昂贵,部署量大的时候,产生的费用也不容小觑。
为什么选HTTP/2?
为了把所有的服务串起来,必须满足的条件有:
- 支持一元RPC调用 (一般的请求/应答模式,类似于函数调用)
- 支持服务器推送(例如pubsub服务,异步通知)
- 支持双向流传递 (网关透传设备数据包到后端,后端应答数据经过网关返回到设备)
我们暂不想自己设计RPC,一是目前RPC繁多,没必要重新发明轮子,二是作为开源项目,应充分融入社区,利用现有资源。我们发现目前http/2(rfc7540)满足以上所有条件,google推出的gRPC就是一个基于http/2的RPC实现,当前架构中,所有的服务(microservice)全部通过gRPC连接在一起。 http/2支持stream multiplex,即可以在同一条TCP连接上,传输多个stream(1:N),stream概念能够非常直观的1:1映射玩家双向数据流。
(请特别注意一点: HTTP/2仅用于服务器各个服务间的内部通信,和客户端的通信是自定义协议,位于:https://github.com/gonet2/tools/tree/master/proto_scripts)
附: HTTP/2 帧封装
+-----------------------------------------------+
| Length (24) |
+---------------+---------------+---------------+
| Type (8) | Flags (8) |
+-+-------------+---------------+-------------------------------+
|R| Stream Identifier (31) |
+=+=============================================================+
| Frame Payload (0...) ...
+---------------------------------------------------------------+
Figure 1: Frame Layout
基本服务模型
+
|
|
+----> game1
|
agent1+------>
|
+----> game2
| +
agent2+------> +-----> snowflake
| |
+----> game3+---->
| |
| +-----> chat
++ |
+-----> rank
+
使用方式假定为:
- 前端用两个部署在不同物理服务器上的agent服务接入,无状态,客户端随机访问任意一台agent接入,比如使用DNS round-robin方式连接。
- agent和auth配合处理完鉴权等工作后,数据包透传进入game进行逻辑处理。如果有多台game服务器,那么用户需要指定一个映射关系(userid->server_id),用来将玩家固定联入某台game服务器。
- game和各个独立service通信,配合处理逻辑。service如果是无状态的,默认采用round-robin方式请求服务,如果是带状态的,则根据标识联入指定服务器。
agent(网关)
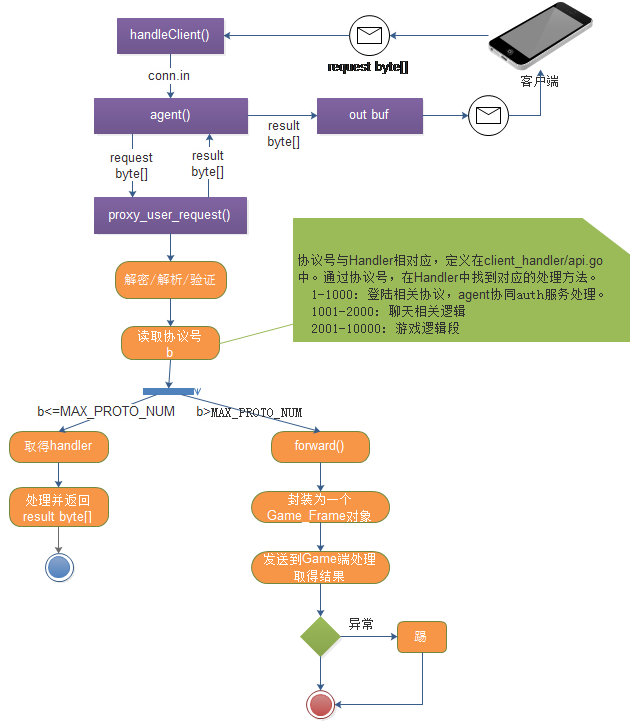
特性
- 处理各种协议的接入,同时支持TCP和UDP(KCP协议),进行双栈通信。
- 连接管理,会话建立,数据包加解密(DH+RC4)。
- 透传解密后的原始数据流到后端(通过gRPC streaming)。
- 复用多路用户连接,到一条通往game的物理连接。
- 不断开连接切换后端业务。
- 唯一入口,安全隔离核心服务。
协议号划分
数据包会根据协议编号(0-65535) 透传 到对应的服务, 例如(示范):
1-1000: 登陆相关协议,网关协同auth服务处理。
1001-10000: 游戏逻辑段
....
具体的划分根据业务需求进行扩展或调整。
消息封包格式
+----------------------------------------------------------------+
| SIZE(2) | TIMESTAMP(4) | PROTO(2) | PAYLOAD(SIZE-6) |
+----------------------------------------------------------------+
SIZE: 后续数据包总长度 TIMESTAMP: 数据包序号 PROTO: 协议号 PAYLOAD: 负载
main.go
// PIPELINE #1: handleClient
// the goroutine is used for reading incoming PACKETS
// each packet is defined as :
// | 2B size | DATA |
//
func handleClient(conn net.Conn, readDeadline time.Duration) {
...
go out.start()
}
agent.go
// PIPELINE #2: agent
// all the packets from handleClient() will be handled
func agent(sess *Session, in chan []byte, out *Buffer) {
proxy_user_request(sess, msg)
}
buffer.go
// PIPELINE #3: buffer
// controls the packet sending for the client
// packet sending goroutine
func (buf *Buffer) start() {
defer utils.PrintPanicStack()
for {
select {
case data := <-buf.pending:
buf.raw_send(data)
case <-buf.ctrl: // receive session end signal
close(buf.pending)
// close the connection
buf.conn.Close()
return
}
}
}
proxy.go
func proxy_user_request(sess *Session, p []byte) []byte {
...
var ret []byte
if b > 1000 {
if err := forward(sess, p[4:]); err != nil {
log.Errorf("service id:%v execute failed, error:%v", b, err)
sess.Flag |= SESS_KICKED_OUT
return nil
}
} else {
if h := client_handler.Handlers[b]; h != nil {
ret = h(sess, reader)
} else {
log.Errorf("service id:%v not bind", b)
sess.Flag |= SESS_KICKED_OUT
return nil
}
}
}
api.go
var RCode = map[int16]string{
0: "heart_beat_req", // 心跳包..
1: "heart_beat_ack", // 心跳包回复
10: "user_login_req", // 登陆
11: "user_login_succeed_ack", // 登陆成功
12: "user_login_faild_ack", // 登陆失败
13: "client_error_ack", // 客户端错误
30: "get_seed_req", // socket通信加密使用
31: "get_seed_ack", // socket通信加密使用
}
...
var Handlers map[int16]func(*Session, *packet.Packet) []byte
func init() {
Handlers = map[int16]func(*Session, *packet.Packet) []byte{
0: P_heart_beat_req,
10: P_user_login_req,
30: P_get_seed_req,
}
}
client_handler/handle.go
// 玩家登陆过程
func P_user_login_req(sess *Session, reader *packet.Packet) []byte {
// TODO: 登陆鉴权
// 简单鉴权可以在agent直接完成,通常公司都存在一个用户中心服务器用于鉴权
sess.UserId = 1
// TODO: 选择GAME服务器
// 选服策略依据业务进行,比如小服可以固定选取某台,大服可以采用HASH或一致性HASH
sess.GSID = DEFAULT_GSID
// 连接到已选定GAME服务器
conn := services.GetServiceWithId("game-10000", sess.GSID)
if conn == nil {
log.Error("cannot get game service:", sess.GSID)
return nil
}
cli := pb.NewGameServiceClient(conn)
// 开启到游戏服的流
ctx := metadata.NewContext(context.Background(), metadata.New(map[string]string{"userid": fmt.Sprint(sess.UserId)}))
stream, err := cli.Stream(ctx)
if err != nil {
log.Error(err)
return nil
}
sess.Stream = stream
// 读取GAME返回消息的goroutine
fetcher_task := func(sess *Session) {
for {
in, err := sess.Stream.Recv()
if err == io.EOF { // 流关闭
log.Debug(err)
return
}
if err != nil {
log.Error(err)
return
}
select {
case sess.MQ <- *in:
case <-sess.Die:
}
}
}
go fetcher_task(sess)
return packet.Pack(Code["user_login_succeed_ack"], S_user_snapshot{F_uid: sess.UserId}, nil)
}
game(逻辑)

设计理念
游戏服务器对agent只提供一个接口, 即:
rpc Stream(stream Game.Frame) returns (stream Game.Frame);
接收来自agent的请求Frame流,并返回给agent响应Frame流
来自设备的数据包,通过agent后直接透传到game server, Frame大体分为两类:
- 链路控制(register, kick)
- 来自设备的经过agent解密后的数据包 (message)
数据包(message)格式为:
协议号+数据
+----------------------------------+
| PROTO(2) | PAYLOAD(n) |
+----------------------------------+
在client_handler目录中绑定对应函数进行处理,协议生成和绑定通过tools目录中的脚本进行。
协议的绑定参考 https://github.com/gonet2/tools/tree/master/proto_scripts
Services(依赖服务)
模块设计约定
- 零配置,配置集中化到coordinator(etcd/consul),即:/etc distributed概念。
- 理论上,唯一可能需要的配置为ETCD_HOST环境变量,用于指定ETCD地址。
- 其他模块特定的参数(SERVER_ID什么的),也通过环境变量指定,docker能方便的设定。
SNOWFLAKE
设计理念
- 分布式uuid发生器,twitter snowflake的go语言版本
- 序列发生器
uuid格式为:
+-------------------------------------------------------------------------------------------------+
| UNUSED(1BIT) | TIMESTAMP(41BIT) | MACHINE-ID(10BIT) | SERIAL-NO(12BIT) |
+-------------------------------------------------------------------------------------------------+
安装
默认情况下uuid发生器依赖的snowflake-uuid键值对必须预先在etcd中创建,snowflake启动的时候会读取,例如:
curl http://172.17.42.1:2379/v2/keys/seqs/snowflake-uuid -XPUT -d value="0"
这个snowflake-uuid会用于MACHINE-ID的自动生成,如果完全由用户自定义machine_id,可以通过环境变量指定,如:
export MACHINE_ID=123
如果要使用序列发生器Next(),必须预先创建一个key,例如:
curl http://172.17.42.1:2379/v2/keys/seqs/userid -XPUT -d value="0"
wordfilter(文字过滤)
设计理念
基于 https://github.com/huichen/sego 实现,首先对文本进行分词,然后和脏词库中的词汇进行比对,时间复杂度为O(m), 其中m为需要处理的消息长度, 和脏词库的大小无关。 基于分词的文字过滤会消耗大量内存, wordfilter至少需要500M内存才能运行,建议每实例配置1GB。
geoip
设计思路
查询IP归属地,基于maxmind的geoip2库做的封装,如果需要最新的准确的数据,需要向maxmind购买。 (query geo-locations of IP, if you need accurate & updated data, please purchase from maxmind.com, thanks. )
问: 为什么选择maxmind的geoip2库? 答: maxmind的geoip2的库设计为一个支持mmap的二叉树文件,查询时间复杂度为O(logN), 文件大小不超过100M,极其紧凑,省内存,速度快,零配置,是目前见过的最好的方案。
日志分析模型
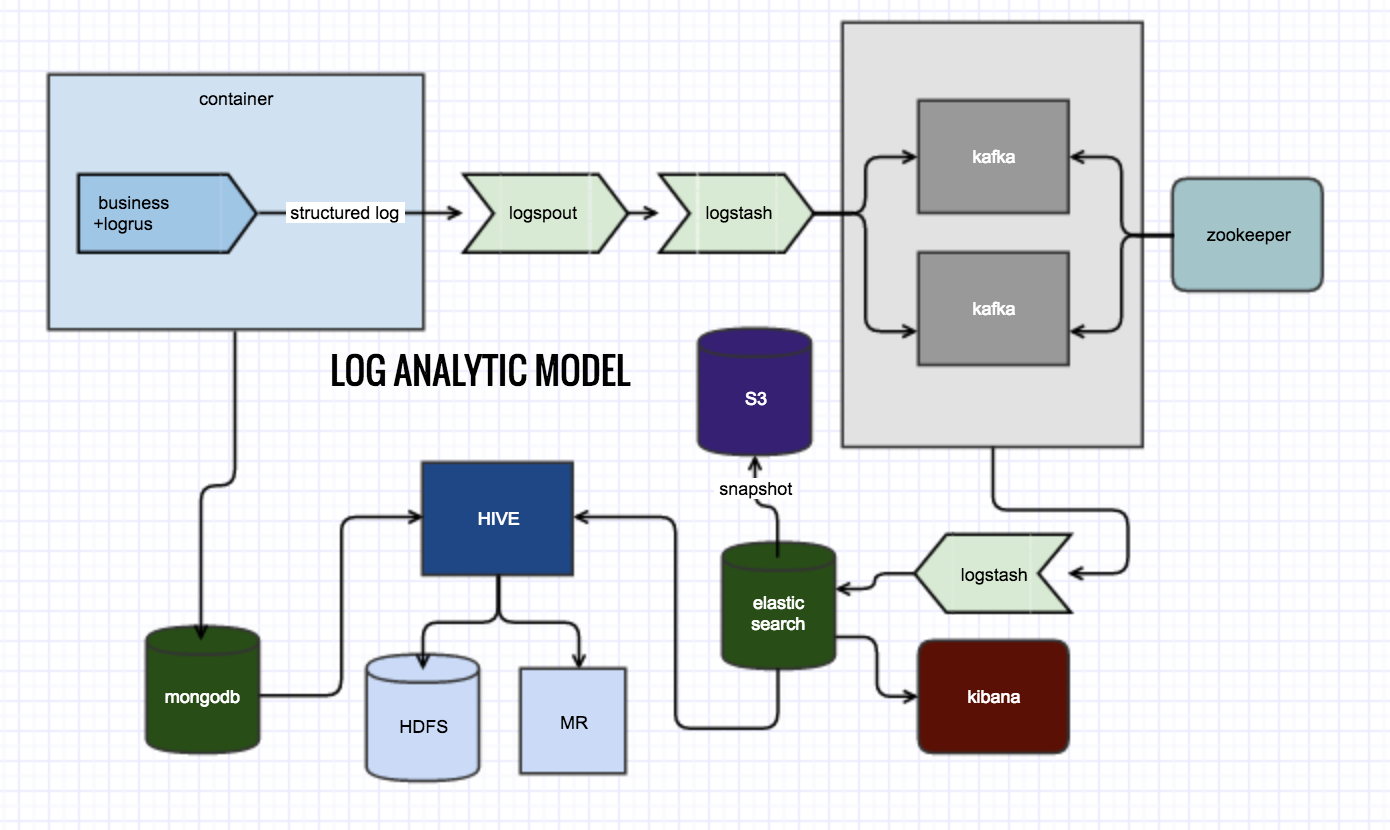
日志分析是通往数据驱动的关键步骤,内容过于庞大,暂留组建图于此。
基础设施
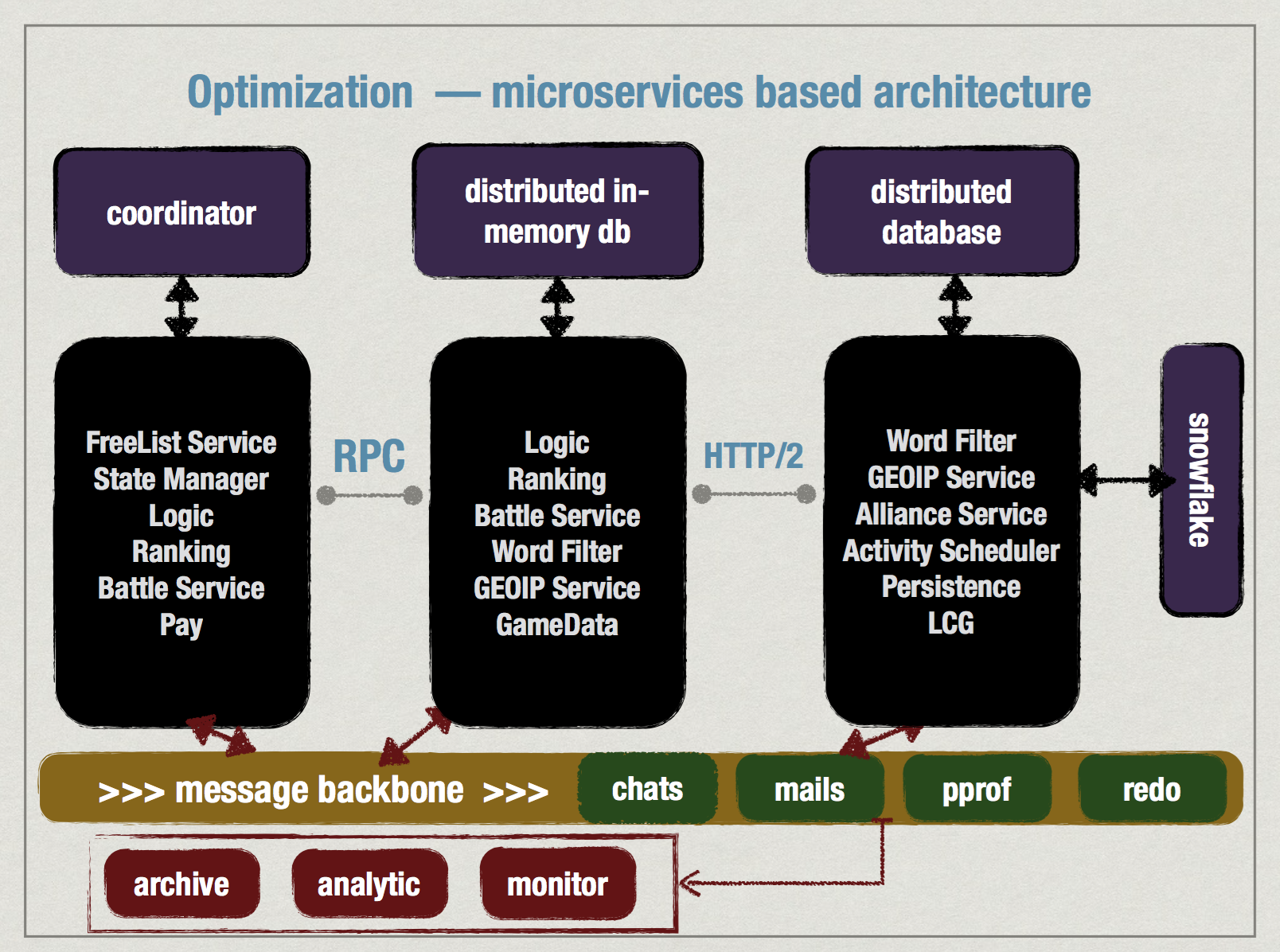
术语:
- coordinator – zk, etcd这种分布式一致性服务。
- message backbone – 服务器件消息总线,通常为pub/sub模式,数据密集。
基础设施是用于支撑整个架构的基石。
链接
资料
Pomelo
Pomelo框架旨在帮助游戏开发者快速建立游戏底层模型,让其更专注于游戏的业务逻辑开发,具有强大的功能,并且灵活可扩展,这些优势与pomelo框架的设计思想是密不可分的。在参照bigworld, reddwarft等成熟游戏框架优秀设计的基础上,结合以往游戏开发经验,确定了pomelo框架的设计思想,下面就对pomelo框架设计思想的核心部分进行阐述。
#概述 在游戏服务器端,往往需要处理大量的各种各样的任务,比如:管理客户端的连接,维护游戏世界端状态,执行游戏的逻辑等等。每一项任务所需的系统资源也可能不同,如:IO密集或CPU密集等。而这些复杂的任务只用一个单独的服务器进程是很难支撑和管理起来的。所以,游戏服务器往往是由多个类型的服务器进程组成的集群。每个服务器进程专注于一块具体的服务功能,如:连接服务,场景服务,聊天服务等。这些服务器进程相互协作,对外提供完整的游戏服务。
由于存在着上述的这些复杂性,游戏服务器端的开发者往往需要花费大量的时间精力在诸如服务器类型的划分,进程数量的分配,以及这些进程的维护,进程间的通讯,请求的路由等等这些底层的问题上。而这些其实都是一些重复而繁琐的工作,完全可以由更专业,更可靠的框架来抽象和封装,从而将上层的游戏开发者解放出来,把精力更多的放在游戏逻辑的实现上面。Pomelo则是一个为了这个目的而生的框架。
从功能职责上来看,pomelo框架结构如下图所示:

- server manager 部分主要负责服务器类型管理,各个进程的创建,管理和监控等。
- network 部分则是负责底层的网络通讯管理,是客户端和服务器之间,各个服务器进程之间通讯的桥梁。同时,network还对底层的细节进行了统一的封装和抽象,对上提供了诸如RPC,channel等基础设施。
- application 部分则是负责每一个进程的具体管理。Application是服务进程的驱动者,是服务进程运作的总入口。同时application也负责维护服务进程的上下文,以及具体游戏服务的配置和生命周期管理等。
下面将围绕着这三部分内容来介绍pomelo框架的设计细节。
服务器类型
Pomelo框架提供了一套灵活,快捷的服务器类型系统。通过pomelo框架,游戏开发者可以自由地定义自己的服务类型,分配和管理进程资源。 在pomelo框架中,根据服务器的职责不同,服务器主要分为frontend和backend两大类型。二者的关系如下图所示:

其中,frontend负责承载客户端的连接,与客户端之间的所有请求和响应包都会经过frontend。同时,frontend也负责维护客户端session并把请求路由给后端的backend服务器。Backend则负责接收frontend分发过来的请求,实现具体的游戏逻辑,并把消息回推给frontend,再最终发送给客户端。在这两类服务器的基础上,可以派生出各种需要的服务器类型,继而生成各种类型的服务器节点。
其实无论frontend也好,backend也好,从上层来看都是一个服务的容器。开发者可以根据容器的职责特性来选择将代码填充到不同的容器中。例如:可以把处理连接的代码放到frontend容器中以获得提供连接服务的服务器类型,而把场景、聊天等代码放到backend容器中获得提供场景服务和聊天服务的服务器类型,如下图所示。也就是说,frontend和backend对外提供什么服务,完全由开发者填充的代码决定。这样,开发者只需要把精力集中在两件事情上:游戏服务器全局的节点分配,以及每个节点上填充的业务代码即可。配置完成后,由Pomelo框架负责将各个服务节点启动并管理起来。

请求/响应流程
请求和响应
游戏服务器的一种驱动源就是客户端发起请求,服务器端进行处理并响应,也就是典型的请求/响应模式。在pomelo中,客户端可以向服务器发送两种类型的消息:request和notify。
Request消息,包含上行和下行两个消息,服务器处理后会返回响应,pomelo框架会仔细维护好请求和响应之间的对应关系;而notify则是单向的,是客户端通知服务器端的消息,服务器处理后无需向客户端返回响应。请求到达服务器后,先会到达客户端所连接的frontend服务器,后者会根据请求的类型和状态信息将请求分发给负责处理该请求的backend服务器,整个流程如下图所示:

请求处理流程
当请求路由到目标服务节点后,将进入请求的处理流程。在pomelo中,请求的处理逻辑主要由游戏开发者完成。请求的处理代码根据职责划分为两大部分:handler和filter。与游戏业务逻辑相关的代码放在handler中完成;而业务逻辑之外的工作,则可以放在filter中。Filter可以看成是请求流程的扩展点。单个服务器上,请求的处理流程如下图所示:

Filter分为before和after两类,每类filter都可以注册多个,并按注册的顺序出现在请求的处理流程上。
Before filter
请求首先会先经过before filter。Before filter主要负责前置处理,如:检查当前玩家是否已登录,打印统计日志等。Before filter的接口声明如下:
filter.before = function(msg, session, next)
其中,msg为请求消息对象,包含了客户端发来的请求内容;session为当前玩家的会话对象,封装了当前玩家的状态信息;next是进入下一环节的回调函数。
Before filter中调用next参数,流程会进入下一个filter,直到走完所有的before filter后,请求会进入到handler中。另外,也可以通过向next传递一个error参数,来表示filter中处理出现需要终止当前处理流程的异常,比如:当前玩家未登录,则请求的处理流程会直接转到一个全局的error handler(稍后会介绍)来处理。
Handler
Before filter之后是handler,负责实现业务逻辑。Handler的接口声明如下:
handler.methodName = function(msg, session, next)
参数含义与before filter类似。Handler处理完毕后,如有需要返回给客户端的响应,可以将返回结果封装成js对象,通过next传递给后面流程。如果handler处理过程中出现异常,也可以像before filter一样处理,向next传递一个error参数,进入error handler处理。
Error Handler
Error handler是一个处理全局异常的地方,可以在error handler中对处理流程中发生的异常进行集中处理,如:统计错误信息,组织异常响应结果等。Error handler函数是可选的,如果需要可以通过
app.set('errorHandler', handleFunc);
来向pomelo框架进行注册,函数声明如下:
errorHandler = function(err, msg, resp, session, next)
其中,err是前面流程中发生的异常;resp是前面流程传递过来,需要返回给客户端的响应信息。其他参数与前面的handler一样。
After filter
无论前面的流程处理的结果是正常还是异常,请求最终都会进入到after filter。After filter是进行后置处理的地方,如:释放请求上下文的资源,记录请求总耗时等。After filter中不应该再出现修改响应内容的代码,因为在进入after filter前响应就已经被发送给客户端。
After filter的接口声明如下:
filter.after = function(err, msg, session, resp, next)
参数含义与error handler的一样。After filter中原则上不应再出现流程控制的逻辑,只需要在完成后置工作后,通过next把前面传递过来的结果继续传递下去即可。
经过after filter链后,如果resp不为空,则该响应会传递到玩家客户端所在的frontend服务器并发送到客户端上。至此,整个请求的处理流程完毕。
Session
Session可以看成一个简单的key/value对象,主要作用是维护当前玩家状态信息,比如:当前玩家的id,所连的frontend服务器id等。Session对象由客户端所连接的frontend服务器维护。在分发请求给backend服务器时,frontend服务器会克隆session,连同请求一起发送给backend服务器。所以,在backend服务器上,session应该是只读的,或者起码只是本地读写的一个对象。任何直接在session上的修改,只对本服务器进程生效,并不会影响到该玩家的全局状态信息。如需修改全局session里的状态信息,需要调用frontend服务器提供的RPC服务。
channel和广播
Channel的作用
在游戏服务器端,经常会遇到需要大量广播消息的场景。比如:玩家test在场景中从A点移动到了B点,我们需要把这个信息广播给附近的玩家,这样大家才能看到玩家test移动的效果。于是我们需要有一个能将消息推送给客户端的途径。而channel则是提供这么一个途径的工具。
Channel是服务器端向客户端推送消息的通道。Channel可以看成一个玩家id的容器,通过channel接口,可以把玩家id加入到channel中成为当中的一个成员。之后向channel推送消息,则该channel中所有的成员都会收到消息。Channel只适用于服务器进程本地,即在服务器进程A创建的channel和在服务器进程B创建的channel是两个不同的channel,相互不影响。
Channel的分类
Pomelo中提供两类channel:具名channel和匿名channel。
具名channel创建时需要指定名字,并会返回一个channel实例。之后可以向channel实例添加、删除玩家id以及推送消息等。Channel实例不会自动释放,需要显式调用销毁接口。具名channel适用于需要长期维护的订阅关系,如:聊天频道服务等。
匿名channel则无需指定名字,无实例返回,调用时需指定目标玩家id集合。匿名channel适用于成员变化频率较大、临时的单次消息推送,如:场景AOI消息的推送。
两种channel对上层的表现形式不一样,但底层的推送机制是相似的。Channel的推送过程分为两步:第一步从channel所在的服务器进程将消息推送到玩家客户端所连接的frontend进程;第二步则是通过frontend进程将消息推送到玩家客户端。第一步的推送的实现主要依赖于底层的RPC框架(下一节中介绍)。推送前,会根据玩家所在的frontend服务器id进行分组,一条消息只会往同一个frontend服务器推送一次,不会造成广播消息泛滥的问题。

RPC框架
RPC的作用
从前面的介绍可以知道,在pomelo中,游戏服务器其实是一个多进程相互协作的环境。各个进程之间通讯,主要是通过底层统一的RPC框架来完成。
在pomelo的RPC框架中,主要考虑解决以下两个问题。
第一个问题是进程间消息的路由策略。由前面的游戏场景分区策略中可以看出,游戏服务是有状态的服务,玩家总与某个场景相关联,场景需要记录玩家在场景中的状态,而相关的请求也必须路由到玩家所在的场景服务中。所以,服务器端的消息路由不单与请求的类型相关,也与玩家的状态相关。比如:玩家A在场景1中移动,则移动的请求应该发往场景1所在的服务进程;而玩家A传送到场景2后,同样的移动请求则需要路由到场景2所在的进程。然而,不同的游戏,状态信息可能会不同,路由的规则也不尽相同。所以,Pomelo框架需要提供一个灵活的机制,让开发者能自由的根据玩家状态控制消息的路由。
第二个问题是RPC底层通讯协议的选择。不同的游戏对服务器之间的通讯协议要求可能也不一样,有的情况可能需要tcp,有的时候可能udp就可以了,再或者需要对传输的数据进行一些加工,如probuffer之类。所以也需要提供一个机制来给开发者来选择和定制他们所需的底层通讯协议。
Pomelo的RPC框架中,引入了多层抽象来解决上述的两个问题。
RPC客户端
在RPC客户端,层次结构如下图所示:

在最底层,使用mail box的抽象隐藏了底层通讯协议的细节。一个mail box对应一个远程服务器的连接。Mail box对上提供了统一的接口,如:连接,发送,关闭等。Mail box内部则可以提供不同的实现,包括底层的传输协议,消息缓冲队列,传输数据的包装等。开发者可以根据实际需要,实现不同的mail box,来满足不同的底层协议的需求。
在mail box上面,是mail station层,负责管理底层所有mail box实例的创建和销毁,以及对上层提供统一的消息分发接口。上层代码只要传递一个目标mail box的id,mail station则可以知道如何通过底层相应的mail box实例将这个消息发送出去。开发者可以给mail station传递一个mail box的工厂方法,即可以定制底层的mail box实例的创建过程了,比如:连接到某个服务器,使用某一类型的mail box,而其他的服务器,则使用另外一个类型的mail box。
再往上的是路由层。路由层的主要工作就是提供消息路由的算法。路由函数是可以从外面定制的,开发者通过注入自定义的路由函数来实现自己的路由策略。每个RPC消息分发前,都会调用路由函数进行路由计算。容器会提供与该RPC相关的玩家会话对象(当中包含了该玩家当前的状态)和RPC的描述消息(包含了RPC的具体信息),通过这两个对象,即可做出路由的决策。路由的结果是目标mail box的id,然后传递给底下的mail station层即可。
最上面的是代理层,其主要作用是隐藏底层RPC调用的细节。Pomelo会根据远程接口生成代理对象,上层代码调用远程对象就像调用本地对象一样。但这里对远程代理对象有两个约定的规则,即第一个参数必须是相关玩家的session对象,如果没有这么一个对象可以填充null,在路由函数中需做特殊处理。还有就是最后一个参数是RPC调用结果的回调函数,调用的错误或是结果全部通过该回调函数返回。而在远程服务的提供端,方法的声明与代理端的声明相比,除了不需要第一个session参数,其余的参数是一样的。
远程服务提供端的方法声明:
remote.echo = function(msg, cb) {
// …
};
代理端的方法声明:
proxy.echo = function(session, msg, cb) {
// …
};
Pomelo框架同时也提供了直接调用RPC的入口,如果上层代码明确知道目标的mail box id,可以直接通过这个接口直接把消息发送出去。
RPC服务提供端
在RPC服务提供端,层次结构相对简单一些,如下图所示:

最底下的是acceptor层,主要负责网络监听,消息接收和解析。Acceptor层与mail box层相对应,可以看成是网络协议栈上同一层上的两端,即从mail box层传入的消息与acceptor层上传出的消息应该是同样的内容。所以这两端的实例必须一致,使用同样的底层传输协议,对传输的数据使用同样格式进行封装。在客户端替换了mail box的实现,则在服务提供端也必须替换成对应的acceptor实现。
往上是dispatch层。该层主要完成的工作是根据RPC描述消息将请求分发给上层的远程服务。
最上层的是远程服务层,即提供远程服务业务逻辑的地方,由pomelo框架自动加载remote代码来完成。
服务器的扩展
每一个服务进程都维护着一个application的实例app。App除了提供一些基本的配置和驱动接口,更多的是充当着服务进程上下文的角色。开发者可以通过app进行一些上下文共享和扩展工作,从而实现各个服务模块之间的解耦。App实例在handler和remote接口中已通过工厂方法注入,另外也可以通过require(‘pomelo’).app来获取到当前进程唯一的app实例。
set 与 get
app.set和app.get的语义与一般的set和get操作的语义一样,即往上下文中保存和读取键值对。开发者可以通过get/set的机制,在app中存放一些全局的属性,以及一些无需生命周期管理的服务对象。
组件
组件的定义
组件(component)是纳入服务器生命周期管理的服务单元。组件一般以服务为单位来划分,一个组件负责实现一类具体的服务,如:加载handler代码,开启websocket监听端口等。App作为服务器的主干代码,并不会参与具体的服务逻辑,更多的是充当上下文和驱动者的角色。开发者可以定义自己的组件,加入到服务器的生命周期管理中,从而来对服务器的能力进行扩展。服务器启动和关闭流程主要就是通过app驱动各个组件启动和关闭的过程。大致流程如下图所示:

组件可以根据需要,提供不同的生命周期接口,pomelo框架会在生命周期的各个阶段触发相应的回调。组件的生命周期接口类型如下:
- start(cb) 服务器启动回调。在当前服务器启动过程中,会按注册顺序触发各组件的这个接口。组件启动完毕后,需要调用cb函数通知框架执行后续流程。
- afterStart(cb) 服务器启动完毕回调。当pomelo管理下的所有服务器进程都启动完成后会触发这个接口。一些需要等待全局就绪的工作可以放到这里来完成。
- stop(force, cb) 服务器关闭回调。在服务器关闭期间,会根据注册顺序的逆序来触发这个回调接口,主要用来通知各个组件保存各自的数据和释放资源。force表示是否要强制关闭。操作完毕后,同样需要调用cb函数来继续后续流程。
组件的加载
组件可以通过
app.load([name], comp, [opts])
接口来完成。
- name 是可选的组件名称。有名字的组件在加载之后可以通过app.components.name来获取。
- comp 是组件对象或组件对象的工厂方法。如果comp是一个函数,则会调用这个函数,同时把app实例和opts当参数传递给这个函数,并把它的返回值做为组件对象。否则直接把comp作为组件对象。
- opts 是一个可选的附加参数,将被传递给comp工厂方法。
服务器抽象的实现
利用目录结构与服务器对应的形式, 可以快速实现服务器的抽象。
以下是示例图:

图中的connector, area, chat三个目录代表三类服务器类型, 每个目录下的handler与remote决定了这个服务器的行为(对外接口)。 开发者只要往handler与remote目录填代码, 就可以实现某一类的服务器。这让服务器实现起来非常方便。 让服务器动起来, 只要填一份配置文件servers.json就可以让服务器快速动起来。 配置文件内容如下所示:
{
"development":{
"connector": [
{"id": "connector-server-1", "host": "127.0.0.1", "port": 3150, "clientPort":3010, "frontend":true},
{"id": "connector-server-2", "host": "127.0.0.1", "port": 3151, "clientPort":3011, "frontend":true}
],
"area": [
{"id": "area-server-1", "host": "127.0.0.1", "port": 3250, "area": 1},
{"id": "area-server-2", "host": "127.0.0.1", "port": 3251, "area": 2},
{"id": "area-server-3", "host": "127.0.0.1", "port": 3252, "area": 3}
],
"chat":[
{"id":"chat-server-1","host":"127.0.0.1","port":3450}
]
}
}
客户端请求与响应、广播的抽象介绍
所有的web应用框架都实现了请求与响应的抽象。尽管游戏应用是基于长连接的, 但请求与响应的抽象跟web应用很类似。 下图的代码是一个request请求示例:

请求的api与web应用的ajax请求很象,基于Convention over configuration的原则, 请求不需要任何配置。 如下图所示,请求的route字符串:chat.chatHandler.send, 它可以将请求分发到chat服务器上chatHandler文件定义的send方法。
Pomelo的框架里还实现了request的filter机制,广播/组播机制,详细介绍见pomelo框架参考。
服务器间RPC调用的抽象介绍
架构中各服务器之间的通讯主要是通过底层RPC框架来完成的,该RPC框架主要解决了进程间消息的路由和RPC底层通讯协议的选择两个问题。 服务器间的RPC调用也实现了零配置。实例如下图所示:

上图的remote目录里定义了一个RPC接口: chatRemote.js,它的接口定义如下:
chatRemote.kick = function(uid, player, cb) {
}
其它服务器(RPC客户端)只要通过以下接口就可以实现RPC调用:
app.rpc.chat.chatRemote.kick(session, uid, player, function(data){
});
这个调用会根据特定的路由规则转发到特定的服务器。(如场景服务的请求会根据玩家在哪个场景直接转发到对应的server)。 RPC框架目前在底层采用socket.io作为通讯协议,但协议对上层是透明的,以后可以替换成任意的协议。
pomelo支持可插拔的component扩展架构
component是pomelo自定义组件,开发者可自加载自定义的component。 component在pomelo框架参考将有更深入的讨论。 以下是component的生命周期图:
总结
以上内容详细阐述了pomelo框架服务器类型划分、请求/响应流程、Channel广播机制和RPC框架以及服务器的扩展等核心部分的设计细想和方案。它们很好的解决了服务器的抽象与扩展、请求响应和服务器间通讯等问题,保证了框架的可扩展、灵活易用性及高性能等特性。在此基础上,游戏开发者就可以避免枯燥乏味的底层逻辑和重复劳动,专注于游戏业务逻辑的开发,按照pomelo框架提供的api文档,结合pomelo快速使用指南,架构概览等文档,便可以轻松的进行游戏开发工作。