kafka in depth analysis
kafka架构分析
Terminology
-
Broker Kafka集群包含一个或多个服务器,这种服务器被称为broker
-
Topic 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
-
Partition Parition是物理上的概念,每个Topic包含一个或多个Partition.
-
Producer 负责发布消息到Kafka broker
-
Consumer 消息消费者,向Kafka broker读取消息的客户端。
-
Consumer Group 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Topology
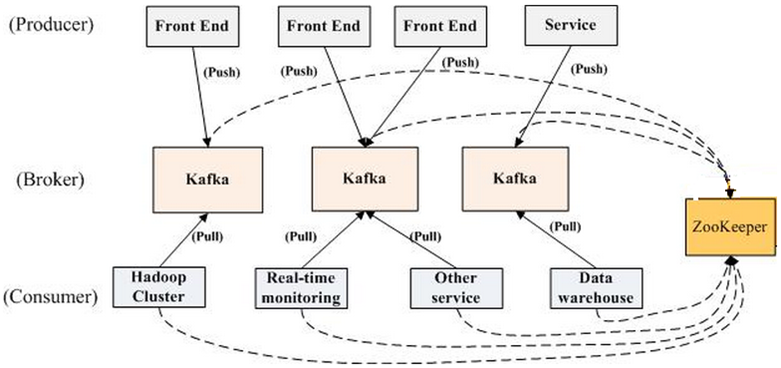
如上图所示,一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
Topic and Partition
Let’s first dive into the core abstraction Kafka provides for a stream of records—the topic.
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
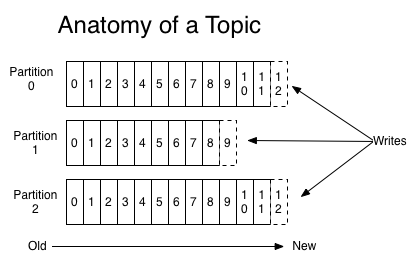
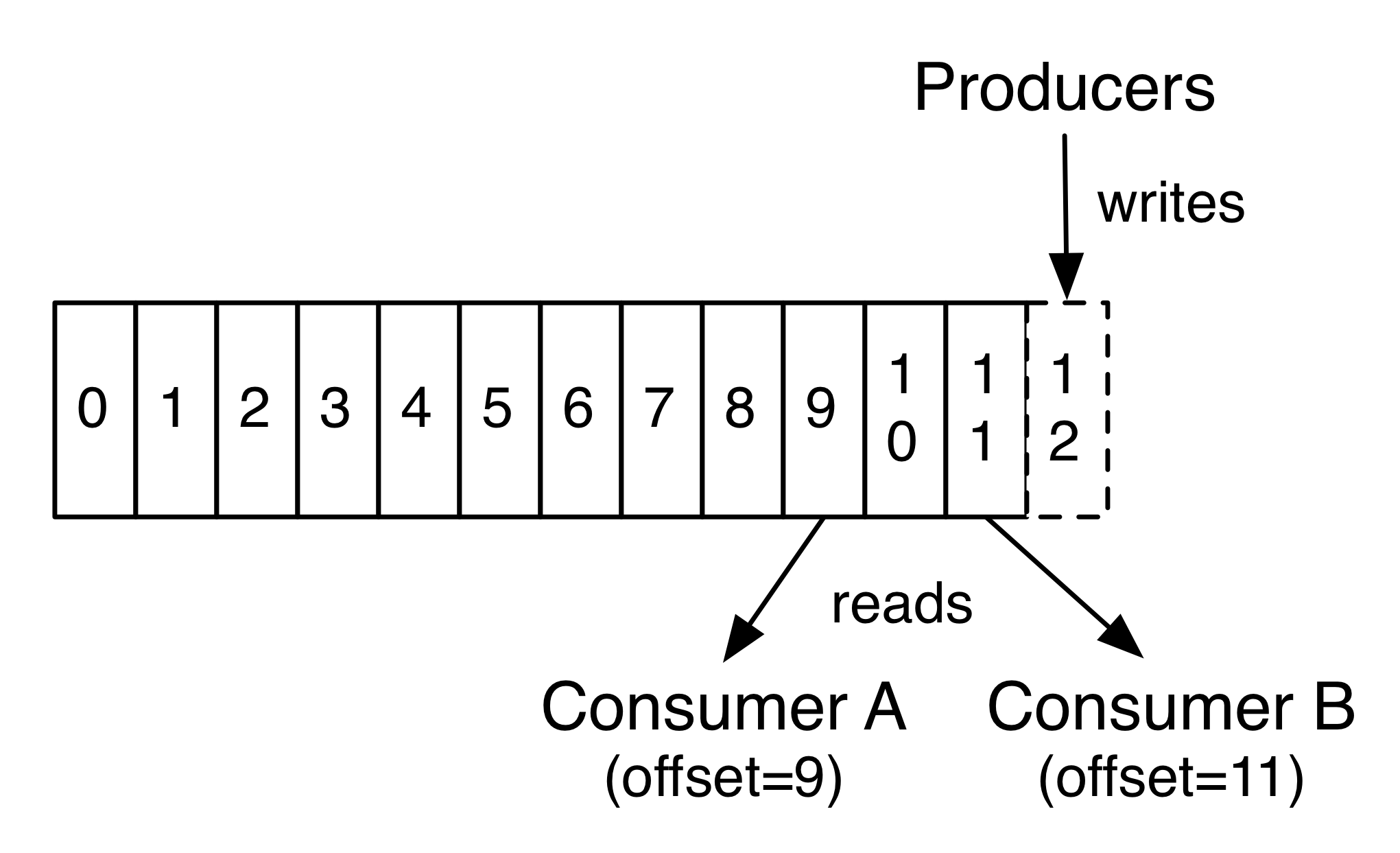
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
The Kafka cluster retains all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka’s performance is effectively constant with respect to data size so storing data for a long time is not a problem.
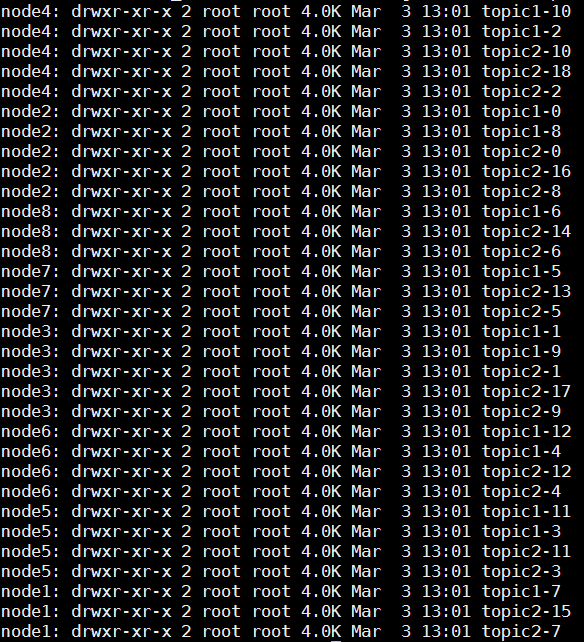
Topic在逻辑上可以被认为是一个queue,每条消息都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集群上会相应会生成共32个文件夹(本文所用集群共8个节点,此处topic1和topic2 replication-factor均为1),如下图所示:
每个日志文件都是一个log entrie序列,每个log entrie包含一个4字节整型数值(值为N+5),1个字节的"magic value",4个字节的CRC校验码,其后跟N个字节的消息体。每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。磁盘上存储的消息格式如下:
message length : 4 bytes (value: 1+4+n)
"magic" value : 1 byte
crc : 4 bytes
payload : n bytes
这个log entries并非由一个文件构成,而是分成多个segment,每个segment以该segment第一条消息的offset命名并以“.kafka”为后缀。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围,如下图所示。
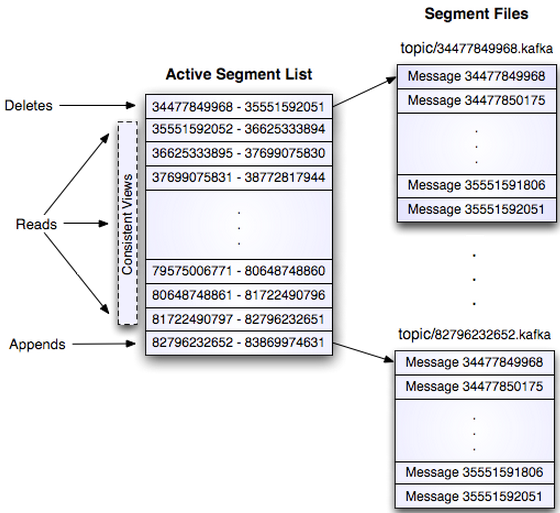
因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
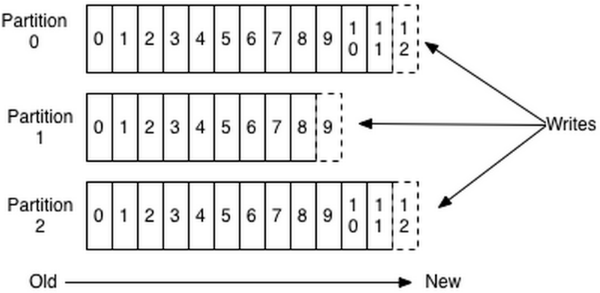
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略删除旧数据。一是基于时间,二是基于Partition文件大小。例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可在Partition文件超过1GB时删除旧数据,配置如下所示。
# The minimum age of a log file to be eligible for deletion
log.retention.hours=168
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according to the retention policies
log.retention.check.interval.ms=300000
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false
因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高Kafka性能无关。选择怎样的删除策略只与磁盘以及具体的需求有关。另外,Kafka会为每一个Consumer Group保留一些metadata信息——当前消费的消息的position,也即offset。这个offset由Consumer控制。正常情况下Consumer会在消费完一条消息后递增该offset。当然,Consumer也可将offset设成一个较小的值,重新消费一些消息。因为offet由Consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些消费过,也不需要通过broker去保证同一个Consumer Group只有一个Consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障
Producer
Producer发送消息到broker时,会根据Paritition机制选择将其存储到哪一个Partition。如果Partition机制设置合理,所有消息可以均匀分布到不同的Partition里,这样就实现了负载均衡。如果一个Topic对应一个文件,那这个文件所在的机器I/O将会成为这个Topic的性能瓶颈,而有了Partition后,不同的消息可以并行写入不同broker的不同Partition里,极大的提高了吞吐率。可以在$KAFKA_HOME/config/server.properties中通过配置项num.partitions来指定新建Topic的默认Partition数量,也可在创建Topic时通过参数指定,同时也可以在Topic创建之后通过Kafka提供的工具修改。
在发送一条消息时,可以指定这条消息的key,Producer根据这个key和Partition机制来判断应该将这条消息发送到哪个Parition。Paritition机制可以通过指定Producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。本例中如果key可以被解析为整数则将对应的整数与Partition总数取余,该消息会被发送到该数对应的Partition。(每个Parition都会有个序号,序号从0开始)
import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
public class JasonPartitioner<T> implements Partitioner {
public JasonPartitioner(VerifiableProperties verifiableProperties) {}
@Override
public int partition(Object key, int numPartitions) {
try {
int partitionNum = Integer.parseInt((String) key);
return Math.abs(Integer.parseInt((String) key) % numPartitions);
} catch (Exception e) {
return Math.abs(key.hashCode() % numPartitions);
}
}
}
如果将上例中的类作为partition.class,并通过如下代码发送20条消息(key分别为0,1,2,3)至topic3(包含4个Partition)。
public void sendMessage() throws InterruptedException{
for(int i = 1; i <= 5; i++){
List messageList = new ArrayList<KeyedMessage<String, String>>();
for(int j = 0; j < 4; j++){
messageList.add(new KeyedMessage<String, String>("topic2", j+"", "The " + i + " message for key " + j));
}
producer.send(messageList);
}
producer.close();
}
则key相同的消息会被发送并存储到同一个partition里,而且key的序号正好和Partition序号相同。(Partition序号从0开始,本例中的key也从0开始)。下图所示是通过Java程序调用Consumer后打印出的消息列表
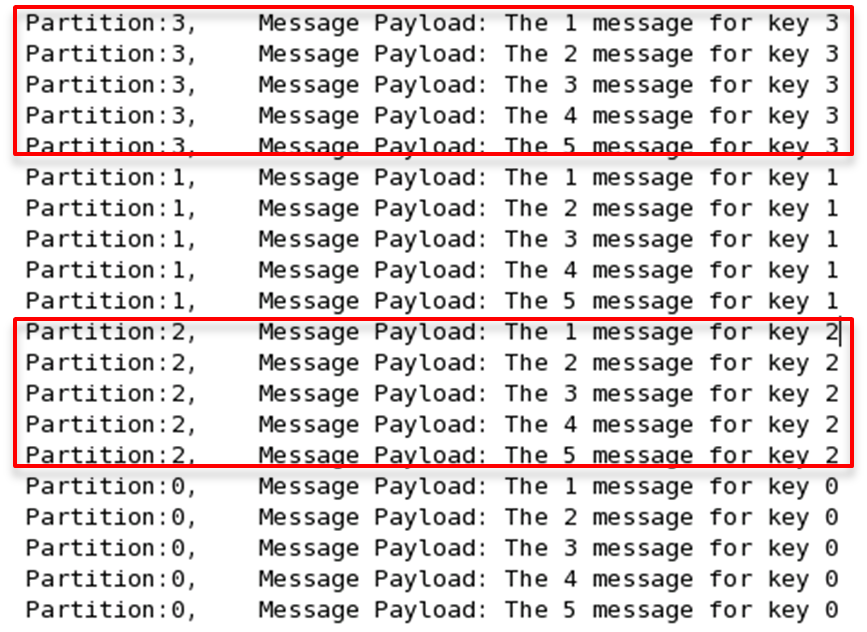
Consumer and Consumer Group
使用Consumer high level API时,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
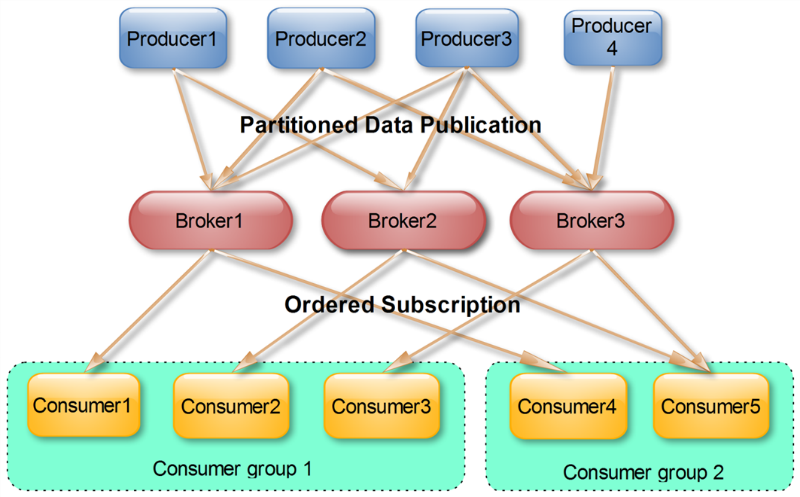
这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。用Consumer Group还可以将Consumer进行自由的分组而不需要多次发送消息到不同的Topic。
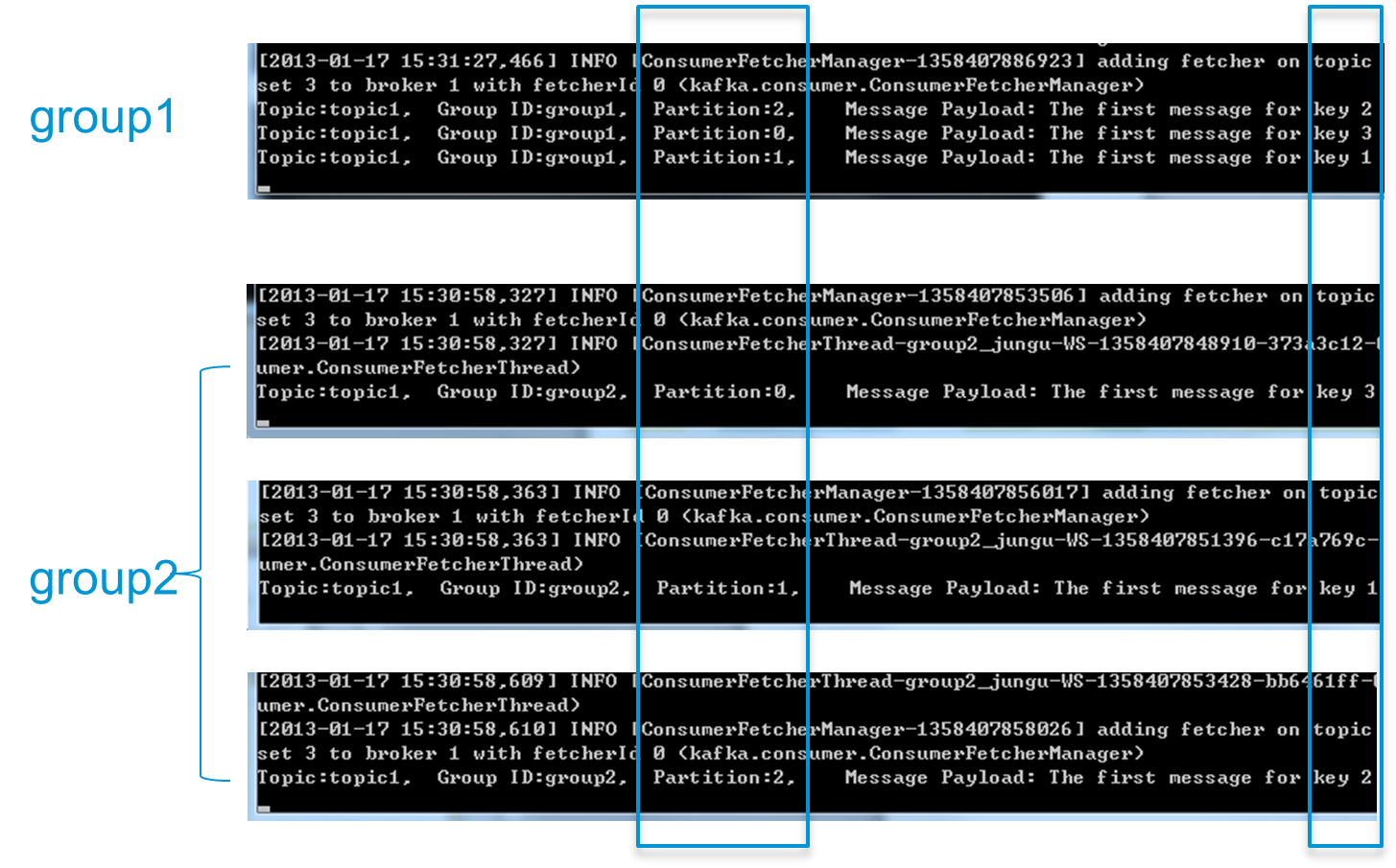
下面这个例子更清晰地展示了Kafka Consumer Group的特性。首先创建一个Topic (名为topic1,包含3个Partition),然后创建一个属于group1的Consumer实例,并创建三个属于group2的Consumer实例,最后通过Producer向topic1发送key分别为1,2,3的消息。结果发现属于group1的Consumer收到了所有的这三条消息,同时group2中的3个Consumer分别收到了key为1,2,3的消息。如下图所示。
HA设计解析
如何将所有Replica均匀分布到整个集群
为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。一个典型的部署方式是一个Topic的Partition数量大于Broker的数量。同时为了提高Kafka的容错能力,也需要将同一个Partition的Replica尽量分散到不同的机器。实际上,如果所有的Replica都在同一个Broker上,那一旦该Broker宕机,该Partition的所有Replica都无法工作,也就达不到HA的效果。同时,如果某个Broker宕机了,需要保证它上面的负载可以被均匀的分配到其它幸存的所有Broker上。
Kafka分配Replica的算法如下:
- 将所有Broker(假设共n个Broker)和待分配的Partition排序
- 将第i个Partition分配到第(i mod n)个Broker上
- 将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
Data Replication
Kafka的Data Replication需要解决如下问题:
- 怎样Propagate消息
- 在向Producer发送ACK前需要保证有多少个Replica已经收到该消息
- 怎样处理某个Replica不工作的情况
- 怎样处理Failed Replica恢复回来的情况
Propagate消息
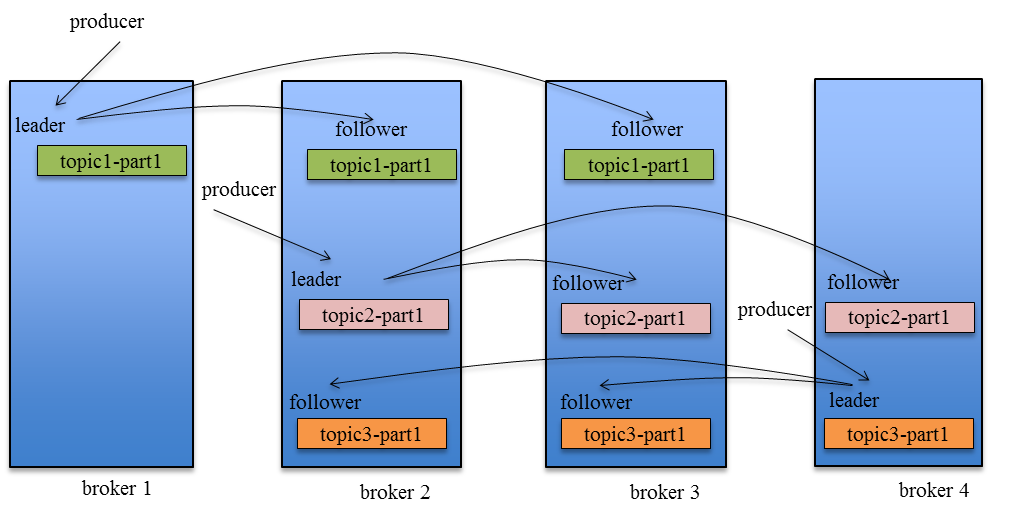
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka会考虑提供更高的持久性。
Consumer读消息也是从Leader读取,只有被commit过的消息(offset低于HW的消息)才会暴露给Consumer。
Kafka Replication的数据流如下图所示:
Basic Kafka Operations
Adding and removing topics
You have the option of either adding topics manually or having them be created automatically when data is first published to a non-existent topic. If topics are auto-created then you may want to tune the default topic configurations used for auto-created topics. Topics are added and modified using the topic tool:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --create --topic my_topic_name
--partitions 20 --replication-factor 3 --config x=y
Checking consumer position
Sometimes it’s useful to see the position of your consumers. We have a tool that will show the position of all consumers in a consumer group as well as how far behind the end of the log they are. To run this tool on a consumer group named my-group consuming a topic named my-topic would look like this:
> bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper localhost:2181 --group my-group
Group Topic Pid Offset logSize Lag Owner
my-group my-topic 0 0 0 0 test_jkreps-mn-1394154511599-60744496-0
my-group my-topic 1 0 0 0 test_jkreps-mn-1394154521217-1a0be913-0
NOTE: Since 0.9.0.0, the kafka.tools.ConsumerOffsetChecker tool has been deprecated. You should use the kafka.admin.ConsumerGroupCommand (or the bin/kafka-consumer-groups.sh script) to manage consumer groups, including consumers created with the new consumer API.
Managing Consumer Groups
With the ConsumerGroupCommand tool, we can list, describe, or delete consumer groups. Note that deletion is only available when the group metadata is stored in ZooKeeper. When using the new consumer API (where the broker handles coordination of partition handling and rebalance), the group is deleted when the last committed offset for that group expires. For example, to list all consumer groups across all topics:
> bin/kafka-consumer-groups.sh --bootstrap-server broker1:9092 --list
test-consumer-group
To view offsets as in the previous example with the ConsumerOffsetChecker, we “describe” the consumer group like this:
> bin/kafka-consumer-groups.sh --bootstrap-server broker1:9092 --describe --group test-consumer-group
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test-foo 0 1 3 2 consumer-1-a5d61779-4d04-4c50-a6d6-fb35d942642d /127.0.0.1 consumer-1
If you are using the old high-level consumer and storing the group metadata in ZooKeeper (i.e. offsets.storage=zookeeper), pass –zookeeper instead of bootstrap-server:
> bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --list
kafka的一些保证:
At a high-level Kafka gives the following guarantees:
-
Messages sent by a producer to a particular topic partition will be appended in the order they are sent. That is, if a record M1 is sent by the same producer as a record M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.
-
A consumer instance sees records in the order they are stored in the log.
-
For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any records committed to the log.
-
对于单个生产者而言,它往某个特定的partition中sent的消息会按照sent的顺序被append到commit log中(被持久化)。意味着如果m1和m2是同一个生产者先后sent的,那么m1在这个partition log中的offset肯定比m2小。
-
对于单个消费者而言,它看到消息的顺序是这个消息被存入partition log的顺序。
-
对于一个有个N个副本的topic而言,kafka最多能容忍N-1个失败(不丢失消息)
消息delivery语义
分为两个问题:the durability guarantees for publishing a message and the guarantees when consuming a message.
对于第一个问题,kafka保证的是那些已经被committed进入log中的消息,能容忍副本数-1个节点的失败以至于不丢消息。同时kafka允许producer指定durability的级别,If the producer specifies that it wants to wait on the message being committed this can take on the order of 10 ms. However the producer can also specify that it wants to perform the send completely asynchronously or that it wants to wait only until the leader (but not necessarily the followers) have the message.
对于第二个问题,consumer的不同的做法有着不同的语义保证:
- 读完消息后,先保存position到broker,然后再处理消息。做到的at-most-once语义
- 读完消息后,先处理,成功后保存position到broker,做到at-least-once语义
- 引入two-phase commit协议保证exactly once
总的来说:
So effectively Kafka guarantees at-least-once delivery by default and allows the user to implement at most once delivery by disabling retries on the producer and committing its offset prior to processing a batch of messages. Exactly-once delivery requires co-operation with the destination storage system but Kafka provides the offset which makes implementing this straight-forward.
kafka用作stream processing
kafka的stream api使得kafka起到和apache storm类似的功能。更多stream的内容见文档。
Replication
topic的一个partition是Kafka进行replication的最小单元,每个partition都有一个leader和0个或者多个followers,一个partition的所有replicas的个数被称为replication factor。所有的读和写操作都由leader来处理。通常而言,集群中有很多个topic,每个topic也有多个partition,数量远多于集群中broker节点数量,这些partition的leader均匀分布在各个broker上。这样一来,当集群中有broker节点失败时,Kafka能够使得受到影响的partition自动在其replicas间failover,从而保持partition的可用性。
用分布式系统的术语来说,Kafka仅试图解决“fail/recover”类型的节点失败,即集群中节点由于某些原因停止正常工作(网络延迟、节点负载增高、fullgc等等),过一会还能够recover过来。Kafka不考虑拜占庭错误(“Byzantine” failure)。
A message is considered “committed” when all in sync replicas for that partition have applied it to their log. Only committed messages are ever given out to the consumer(注意这句话,只有committed的消息才会交给consumer).This means that the consumer need not worry about potentially seeing a message that could be lost if the leader fails. Producers, on the other hand, have the option of either waiting for the message to be committed or not, depending on their preference for tradeoff between latency and durability. This preference is controlled by the acks setting that the producer uses. The guarantee that Kafka offers is that a committed message will not be lost, as long as there is at least one in sync replica alive, at all times.
Replicated log
kafka的partition的核心就是一个replicated log。那么什么事replicated log呢?其实它是对一系列值的顺序达成一致性的处理过程的建模,就是分布式一致性协议所要解决的问题。最简单的实现方式就是:一个leader负责确定值和其顺序,其他的follower只是简单的copy leader达成的结果(raft算法就是这样的)。
如果leader不会挂掉的话,那就没有follower什么事了。当leader挂掉时我们需要从follower中选择一个新的leader,但是follower本身也可能落后leader很多或者挂掉,因为我们必须保证所选的是一个up-to-date的follower。因为这里就得出一个tradeoff:如果leader在宣称一条消息被commit前等待越多的follower,那么就会有越多的leader候选人,当然也就意味着更长的等待时间。
一个通常的做法对commit decision和leader election都采用majority vote(即过半,当然kafka并不是这样做的,但值得了解下)。具体来说:假设我们有2f+1个replicas,如果现在要求一条消息在被leader commit前必须有f+1个replicas收到了这条消息,此时我们选择一个新的leader只需要从任意f+1个followers中选择log最完整的那个follower即可,因为这个新的leader一定有所有的committed log(因为任意f+1个follower中至少有一个有up-to-date的replica),这也意味着可以容忍 (2f+1) - (f+1) = f个节点失败。
这种majority vote方法在commit decision时具有一个很好的性质:延迟取决于最快的那些节点。ZK的zab协议、raft、viewstamped replication等都是属于这一类。
majority vote的缺点在于,它可以容忍的失败节点数有限,意味着为了容忍一个节点失败集群中必须要有三份数据的拷贝;容忍两个失败则要求5份数据拷贝。经验表明在生成环境中只容忍一个节点失败是不够的,至少两个,但是对于大容量的数据存储系统而言,5份数据拷贝也是很不现实的,这也是为什么这种quorum算法通常用于集群配置管理(比如ZK)而不是数据分布式存储。比如在HDFS中,namenode的高可用基于majority-vote算法,而数据本身并不是。
kafka在选择commit decison的quorum set时所采取的方法有点不同,它动态地维护一个in-sync replicas集合(ISR),集合中所有的replica都catch up着leader。只有这个集合中的节点才能被选为leader。一个对partition的写操作只有当所有ISR中节点都收到后,才会被认为是committed。ISR集被持久化在ZK中。理想情况下,ISR集中有所有的follower,但只要ISR集中有一个节点,那么集群就被认为是可用的(其他节点都fail了)。因此,对于f+1个replicas而言,kafka可以容忍f个节点失败。相比majority vote而言,“延迟取决于最快的那些节点”这个性质就没有了。
durability vs availability
假设我们运气不好,所有的replicas都fail了,而且不巧leader也挂了需要选主,此时将面临两个选择:
- 等待ISR集中的replica恢复过来,选择这个节点作为新的leader
- 选择最先恢复过来replica(不一定是ISR的)作为leader
这就是一个简单的consistency和availability的tradeoff。默认情况下,kafka采用的是第二个策略,这种行为被称之为“unclean leader election”。当然kafka提供配置禁用掉这个行为。
当durability的重要性高过availability时,可以采用如下两个topic-level的配置:
- disable掉unclean leader election
- 指定一个最小的ISR集大小,只要在ISR集大小大于这个值时kafka才提供写操作(这个配置需要和producer在ack级别是all才能真正起作用)
replica management
上面关于Replicated log选主过程的讨论是仅针对单个topic的某个partition而言的,事实上,Kafka集群管理着成百上千个这样的partitions,分布在不同的broker节点上。也就是说集群中有很多的leaders,那么优化选主过程对可用性也是非常重要的。Kafka在集群的所有broker中选择一个broker作为“controller”,由这个controller在broker级别负责检测其他broker节点的fail情况,并负责给那些failed的broker上受到影响的partitions选主。这样做的结果就是所有选主操作都由controller负责,多个partition的leadership变动通知也可以做到批量发送,选主过程变得简单快速。如果controller挂掉了,那么剩下的broker节点将进行新的controller选举(即broker层面的选主)。